言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議(ことば文化特設サイト)
ことば文化に関する気になるトピックを短期連載で紹介していきます。
-
- 2024年01月23日 『近刊(12月)のお知らせ→https://la-kentei.com/kotoba_news/?category=9』
-
リベラルアーツコトバ双書から近刊(12月末刊行予定)のお知らせです。第7巻は岸山健先生が連載を改稿したもので、より言語学的側面に焦点を当てて体系だった形式になるとのことです。詳細は時期が近づき次第告知予定です。(野口)
新刊情報(リベラルアーツコトバ双書)
第6巻:渡部直也著. (3月末刊行予定). 『ウクライナ・ロシアの源流 --スラヴ語の世界--』.
既刊情報(リベラルアーツコトバ双書)
第5巻:野口大斗著. (2023). 『自然言語と人工言語のはざまで --ことばの研究・教育での言語処理技術の利用--』.
第4巻:黄竹佑・岸山健・野口大斗著. (2023). 『jsPsych によるオンライン音声実験レシピ』.
第3巻:河崎みゆき著. (2023). 『中国のことばの森の中で --武漢・上海・東京で考えた社会言語学--』.
第2巻:川原繁人著. (2022). 『言語学者、外の世界へ羽ばたく --ラッパー・声優・歌手とのコラボからプリキュア・ポケモン名の分析まで--』.
第1巻:岸本秀樹著. (2021). 『日本語のふしぎ発見! --日常のことばに隠された秘密--』.
-
- 2024年01月16日 『新刊(3月)のお知らせ』
-
リベラルアーツコトバ双書から新刊(3月末刊行予定)のお知らせです。第6巻は「ウクライナ・ロシアの源流 --スラヴ語の世界」です。渡部直也先生が連載を改稿したもので、より社会的な側面に焦点を当ててスラブ語の世界を描かれます。戦争の時代にスラブ語の研究をしている若手による貴重な記録です。目次は3月上旬に書籍刊行情報欄から公開予定ですので、ぜひチェックしてください。(野口)
既刊情報(リベラルアーツコトバ双書)
第5巻:野口大斗著. (2023). 『自然言語と人工言語のはざまで --ことばの研究・教育での言語処理技術の利用--』.
第4巻:黄竹佑・岸山健・野口大斗著. (2023). 『jsPsych によるオンライン音声実験レシピ』.
第3巻:河崎みゆき著. (2023). 『中国のことばの森の中で --武漢・上海・東京で考えた社会言語学--』.
第2巻:川原繁人著. (2022). 『言語学者、外の世界へ羽ばたく --ラッパー・声優・歌手とのコラボからプリキュア・ポケモン名の分析まで--』.
第1巻:岸本秀樹著. (2021). 『日本語のふしぎ発見! --日常のことばに隠された秘密--』.
-
- 2024年01月09日 『新刊(2月)のお知らせ』
-
岸本秀樹先生がシリーズエディターを務めるリベラルアーツ言語学双書から新刊(2月末刊行予定)のお知らせです。第3巻は「やわらかい文法」と題して、定延利之先生によって書き下ろされました。定延先生の18年ぶりとなる一般向けの書籍です。目次は2月上旬に書籍刊行情報欄から公開予定ですので、ぜひチェックしてください。(野口)
既刊情報(リベラルアーツ言語学双書)
第2巻:天野みどり著. (2023). 『日本語の逸脱文--枠からはみ出た型破りな文法--』.
第1巻:西山國雄著. (2021). 『じっとしていない語彙』.
-
- 2024年01月02日 『休載(1月)のお知らせ』
-
10月から12回にわたり、「言語学闇鍋エンジニアリング」と題して、言語にまつわる計算機を使った話題を提供してくださった岸山先生、ありがとうございました。今年刊行予定の新書では改稿のうえ新たな話題も盛りこまれるとのことです。ぜひ、新書にもご注目ください。
今年の連載は3つとなり、1月と5月、9月はお休みの予定となっております。(野口)
-
- 2023年12月26日 『12. 言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議:アンチパターン 岸山健(法政大学文学部英文学科ほか非常勤講師)』
-
アンチパターン
最後に、ここまで共有してきた話の対象読者と目的を再び言語化し、エンジニアリングから学んだ「アンチパターン」を共有したい。ここまでの対象読者は言語に対する興味を持っている人だった。高校生くらいの自分でも、あるいは現在の友人や同僚でも、すべてとは言わないがある程度は楽しめる内容にしたかった。目的としては、(a)ネットに落ちている知識を少し深掘りした専門性を与えつつ、(b) 計算機を使ってこそわかる事柄を伝えることだった。
目的の(a)は部分的にでも達成できたと思う。ハリポタツアーやMTGの話は深く掘れたと思うし、(b)に関しても感想や音の可視化、AIの利用は計算機だからこそ伝えられる内容だった。言語の階層から考えると音→単語→統語と進むように思えるが、音よりも語彙の方が話のネタとしてわかりやすいので単語→音→統語と進めた。
全体を通して、計算機が可能にするケーススタディを多分に持たせた。単純に、これが筆者だからこそ書ける内容だったというのもあるが、実はもう少し野望めいたこともあった。なぜわざわざ読者にとってなじみのないであろう計算機を導入したのだろうか。
その説明には筆者が勝手に持っている未来予想を共有しないとならない。もちろん予想なので反証可能性は持っているが、社会的にはむしろ反証されたほうがよろこばしいと思う。その予想というのは、以下のようなあまりうれしくないシナリオになる。
人手不足が進む日本では今後、業務の効率化がより強く求められるようになり、AIの研究やAIの活用方法の模索が進む。DXを旗印にプログラミングやデータサイエンスの需要が高まり中学や高校でも必修化が進む。ビジネスでの活用から大学や社会人の需要も高まり、研究や教育での活用から大学院での活用も進む。ただ、学ぶ前は「これをやって何の役に立つのか」が実感できず手が動かない人が増える。
そういう手の動かない人に効く万能なアプローチはない。なにしろ学習は動機あってこそだ。ただ、その人たちの中に言語に興味を持っている人がいたとしよう。語彙や音、文の構造、あるいはその運用に興味を持っている人たちだ。この人たちにとっては、自分の好きなトピックを使ったプログラミングの本が役立つかもしれない。だからこの文は、将来発生するであろう読者に対しても書いている。
もちろん、たまたま読んでいる人もいると思う。そういう人に対して望むものは、書かれている内容の抽象化と具体化の手順だ。たとえば、感想をベクトルにして分類するという具体例を単に「(何かを)数値にして分類する」として、学習者の分類などに応用にしてもよい。自分の分野に転用してみてほしい。
つぎに研究者とエンジニアの視点から、コードを伴わない個人的に好きな6点の概念を共有する。これらは筆者の心の片隅に住み着いているソフトウェア開発のアンチパターン(つまり「べからず集」)だ。エンジニアだけでなく基本的な思考にも応用可能だと思うのでぜひつき合ってほしい。目の前にある問題に取り組む方法や解決するときのコツ、解決の進め方についてだ。
車輪の再発明
自分が抱えている問題に対して、ものすごく賢い方法を思いついたとする。ここでまずすべきことはなんだろうか。しばらくよろこんだあと、すぐに他の人に出し抜かれないうちに作って公開することだろうか。いや違う。よろこぶのも着手するのも気が早く、まずは先行事例の調査することだ。方法を考える前に先行事例を調査するのが先な気もするが、なぜかゼロから考えようするケースは自分を振り返ってみてもよくある(1)。
こういう、すでに存在する効率的な手段を改めて自分で発明してしまう行動を「車輪の再発明」とエンジニアは呼ぶ。さらに、再発明した物が既存の物より使えない場合は「四角い車輪の再発明」なんて呼ぶこともある。研究で必要なコードを自分で作るより、既存のコードを使ったほうが効率的だったりメンテナンスが容易だったりし、そもそも工数が少ないので効率的だ。筆者は常に「自分程度が思いつくアイデアはすでに存在するはずだ」という前提を胸に刻んでいる。
新奇性を求められる研究でも同じだ。大学のころ、先生がこんな問いかけをした。
もし自分の仮説をほかの誰かが発表していたときの研究者の発想はどちらだろうか。
1. やった、あの有名な先生と同じ考えを持てていた!
2. やられた!
もちろん、正解は2だ。研究者としてはおそるおそる先行事例を調べて、エンジニアとしてはメンテナンスで楽をしたくて調べる。
ちなみに、どちらも「巨人の肩」という概念に通じるものがある。研究者としては、今の研究は過去の研究に基づいているので肩の上にいる。エンジニアとしても、今のソフトウェアは多くの開発に基づいているのでこちらも肩の上にいる。新しい巨人を作るのは大変だが、巨人の一部にはもしかしたらなれるかもしれない。ここら辺は大学のころに先生が言っていた「一番高いピラミッドを作るのは現状のピラミッドの上に石を一つ置くだけでいい」と言っていたのに近い。
銀の弾丸
自分がかなりパワフルな解決方法をもっているとする。筆者だったらパソコンとかGitとかTeXとかPythonとかかもしれない。実験機材を持っている人がいるならば、高い機材があってそれは価格に見合う性能を持っているんだと思う。これらは銀の弾丸、つまりあらゆる狼男や悪魔を倒せる武器になりえるだろうか。
こういう「すべての問題を解決する手段」のことを「銀の弾丸」とよび、エンジニアとしては「銀の弾丸は存在しない」という前提を胸に刻んでいる。つまり、自分が使えるソフトやハードが全てを解決することはなく、おそらく適材適所という物があるだろうという前提を持つことに繋がる。
これの悪い例をいくつか考えてみると、すべてAIで解決しようとするケースが典型だろう。計算効率から考えても単純なモデルの方がいいのにわざわざ巨大なモデルを走らせたり、画像を使えばいいのにわざわざテキストのみを使ったり。なんでこんなことが起きるのだろうか。
これには「マズローのハンマー」という別のアンチパターンが存在する。これは「ハンマーをもっている人間には全ての問題が釘に見える」というものだ。たまに自分でも、ネジをハンマーで叩こうとしていることに気づくので、まずは問題(ここでいえばネジ)に自分のツールがあっているかを確認する癖をつけたい。
前に知り合いの研究者が「でかいハンマーを持つと釘を探すようになる」と言っていた。でも、それ自体には良いも悪いもない。最終的にその人が解決できることを解決しきれるのならばそれでよい。大切なのはハンマーでネジを叩き続けないことだ。解決すべきが釘でもネジでもよいなら好きな方を選べばよいし、決まっているならポケットに入っている道具を思い出せばよい。
スコープ・クリープ
何か問題に取り組んでいると、あれもこれもと手を伸ばしたくなることがある。いま取り組んでいる課題の前提って正しいのだろうか。ほかにこんな機能を追加したらよいのではないのだろうか。前提を疑うのは非常に大事だし、その機能も専門的には必要な機能だろう。もともとの目的とずれていく。こうした対象(スコープ)がジリジリとズレる(クリープ)現象はスコープ・クリープと呼ばれる。
ズレることによる責任を自分で取れるなら問題ない。余計に時間やお金がかかるけど、その対価を受けるのが自分であれば正負を問わず飲めばよい。ただ、そのズレというリスクを他人に押し付けるのは問題だ。納期が間に合わなかったり、期待されていた挙動とズレていたり。個人なら許容できるかもしれないが、チームなら許容できない。
筆者もこうした経験はよくあったし、今でもたまにやらかす。大抵は対話不足や、課題の共有はできていても解決したい問題をくみ取れていない場合に起こる。問題を解決したい人と課題に取り組む人が同じなら高速でPDCAを回せるが、そうでない場合は中継に必要な人数分だけ動きが遅くなる。
前提を疑うなら前提を疑うのをタスク化しよう。他に機能を追加したいなら機能の追加をタスク化しよう。あるタスクに取り組んでいる時に別のタスクに取り組んでしまうと、停止条件を設けない限り再帰的にタスクが発生してしまう。関連する表現は “Done is better than perfect” になる。こちらも肝に銘じている。
スパゲティーコード
研究においてもビジネスにおいても再現性は大事だと思う。ビジネスサイドの人と話していると「研究ってビジネスと似ているのですね」と言われることがある。研究における再現性は、論文のMethod章や付随する資料を利用してResults章を再現できるかにかかっている。そのためには分析の時点からある程度はきれいに書かないとならない。
この点に関しては『再現可能性のすゝめ 』という書籍がおすすめで、分析スクリプトで注意すべき点が書いてある。たとえば、この分析Aをしてつぎの分析Bをして...と手順を決めてしまうと、時系列順に並んでいればよいが順番が崩れたら大惨事だ。実行する順序で結果が変わるという事故につながりかねない。このような依存関係がスパゲティーのように絡まる状態は避けたい。
1枚のファイルに分析をまとめてしまうのがよい。なんども実行しなければならない時間のかかる処理があるなら、ボトルネック(つまり処理の速度を遅くするポイント)を特定してキャッシュして過去の処理を使いまわせるようにするとよい。そうすれば、すべきことは常に「全体の実行」となり、実行順序のスパゲティーは解決する。
順序がスパゲティーになっているのも悪いが、変数が複雑に絡み合っているのもよくない。つまり、ある変数が上の方で定義されて、下の方で再定義されるようなケースだ。これも変数間の行間が空きすぎてしまっていたり、複数の変数に影響を与える複雑な絡み方をしていたりする場合、その変数を変更することが思わぬ副作用を生む場合がある。
したいタスクがあれば適度に関数にまとめよう。関数内のスコープなら全体のスコープを汚染しないですむ。困難は分割せよという言葉があるが、問題を課題に分割して個別に対処するようにすれば、スパゲティーの範囲は分割した範囲に制限されて見通しがよくなる。こうした可読性の向上には『リーダブルコード』も必読書だ。
『リーダブルコード』はエンジニアならほとんどの人が耳にしたことがある書籍で、上司から勧められた、あるいは会社の本棚で見かけたことがある人も多いだろう。個人的には結城浩先生の『数学文章作法 推敲編』のプログラミング版的なポジションになっている。
今はまだ自分の研究のコードはシンプルかもしれないが、将来的に肥大化するリスクをヘッジするためにも、コーディングするすべての研究者におすすめしたい。
早すぎる最適化
スパゲティーコードがよくないのはわかった。時間的な順序や変数間が絡まると再現性を落としてしまう。コードの可読性を改善しよう。大きな処理は分割したり、変数にわかりやすい名前をつけたり、変数のスコープを狭めたり、流れをわかりやすくしたり、コメントを調整したり、美しくしたりする。でもどのタイミングで手を加えればよいのだろうか。
見た目を美しく保つのは気にしすぎてはならない。インデントを揃えたり、Rなら=と<-を揃えたり、そういった作業は人間がすることではない(2)。この手の作業はlinterを使うとよいだろう。もともとlintとはソースコードの構文や型などをチェックするツールだったが、今では一般的な呼称になっている。RにしろPythonにしろ、そうした自動化できるチェックは自動でやるのがベストだ。
この早すぎる最適化は論文を書くときでもスライド作りなどでも同じだ。何度か言及している『数学文章作法 推敲編』も、書き始めから気にしていたら進まない。書きやすさを優先し、大枠を先に作ってから文を最適化していく。細かな枝葉を整えても文章の骨子が組み替えられれば修正が必要になる。大きな部分から固めていくのを優先し、細かい部分の最適化は後回しにするとよい。
ただ、細かい自動的なチェックによりプログラムは書き換えられる場合がある。そこでGitなどの分散バージョン管理システムを導入する必要がある。再現性の本でも文章作法の本でも導入が推奨されているのにも関わらず、実際に使う人は驚くほど少ない。確かに学習コストが高いのはそうだが、分析スクリプトを書く人にとっては必須になる。
もちろん、これも銀の弾丸ではない。Gitなどの分散バージョン管理が光るのは、データや分析スクリプト、原稿といったファイルが、ディレクトリ単位でバージョンの一致を求めるケースだ。それ以外の、他のファイルに依存しない研究計画書や原稿などはGoogle Docsなどで管理すればよく、共同編集や履歴の保存といった所望の機能は得られるのでハンマーに振り回されることもない。
砂上の楼閣
研究でもエンジニアリングでも自分の努力のベースに何を置くかは注意したい。修士のころに研究発表をしたとき、その場にいた人から「その先行研究にのみ依存しすぎるのは危険ではないか」という指摘を受けたことがある。自分の仮説がその研究にのみ依存していると、その仮説が反証されたときに困らないかという話だった。
いわゆる「砂上の楼閣」とは、崩れやすい砂の上に建てた高い建物、つまり不安定な地盤に作られた立派なものを意味する。エンジニアのアンチパターンとしては、外部に極度に依存したシステムを意味する。たとえば、OpenAIのAPIやStreamlitが提供するCommunity Cloudへの依存が好例だ。
これに対する対策としては、もちろん自前で用意する準備をしておくというのもありだろう。アイデアを形にするのは外部要素で手早くして、後から自前のものに置き換えていく。ただ、ほかにも代替として別の外部要素を検討するというのもよい。外部要素に依存している状態は変わらないが、リスクは分散される。
このリスク分散の考え方はシステムの冗長性に関係する。人間の音声知覚も情報が落ちても成り立つが、システムも要素が欠けても問題ない状態にするのが肝要だ。これはDiversificationというリスク分散の考え方や、もっと面白い発想でいくと意図的に障害を起こす「カオスエンジニアリング」というのもある。この多様化や冗長性という発想はどこまで一般化できるのだろうか。
よく聞く身近な話としては、家族や職場意外にコミュニティを3つくらい入っておくというのは精神の安定に貢献するという。仕事はどうだろうか。ジョブ型に雇用がシフトして副業が推奨されるのは、このリスク分散と複数技能のシナジーを期待されている気がする。もしかすると、数百年後には親子の関係やパートナーも分散するのがサポートされるかもしれない。
気をつけたいのは、1つの機能に対する依存先を複数用意するというは、複数に依存するという話ではない点だ。この機能はあのAPI、この機能はあのライブラリ、と依存関係を増やすと、依存先同士が依存したり、どれかが欠けたりするリスクが増える。そういうケースはできるだけ避けたい。
ほかにも共有したいエンジニア的な発想はたくさんある。「アジャイル開発」という考え方は筆頭だ。書籍としては『アジャイルサムライ』が包括的で、カンバンやテスト駆動開発、継続的インテグレーションという概念を導入している。ただ、分かりやすいのは実際にプロジェクトに参加してハンズオン形式で学ぶことだろう。
ビジネスにしろ研究室にしろ(あるいは家族や友人関係でも)、チームで問題に立ち向かう局面は必ず発生する。エンジニアではその分野の性質上、ITを駆使して現状における最高の手法を採用している。エンジニアでない人も、きっとその手法を抽象化して自分のキャリアや研究、生活に反映させる方法を見つけられると思う。変化が激しい時代、こっちも学んで変化し続ける方が楽に思えるので、ぜひ覗いてみてほしい。
参考文献
結城, 浩. (2013). 数学文章作法基礎編. 筑摩書房.
Rasmusson, J. (2011). アジャイルサムライ――達人開発者への道 (西村直人, 角谷信太郎, 近藤修平, & 角掛拓未, 訳.). オーム社.
Boswell, D., & Foucher, T. (2012). リーダブルコード: より良いコードを書くためのシンプルで実践的なテクニック (角征典, 訳.). オライリー・ジャパン.
高橋, 康介. (Ed.). (2018). 再現可能性のすゝめ. 共立出版.
(1) 調べるより作った方が早いというケースもある。
(2) https://www.tidyverse.org/blog/2017/12/styler-1.0.0/
-
- 2023年12月12日 『10. 言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議:頼もしい相棒 岸山健(法政大学文学部英文学科ほか非常勤講師)』
-
頼もしい相棒
 図1. 唯一賞賛されたキーボード。お目が高い、静電容量無接点方式キーボードだ。ただこれも「物置で拾ってきたの?」と言われたことがある。
図1. 唯一賞賛されたキーボード。お目が高い、静電容量無接点方式キーボードだ。ただこれも「物置で拾ってきたの?」と言われたことがある。
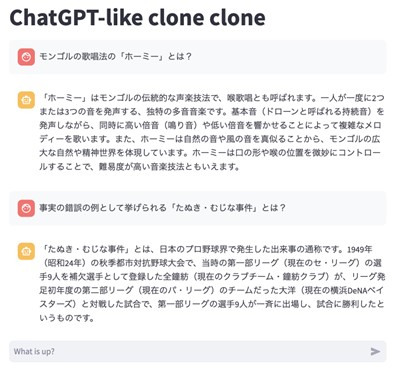 図2. 無料で使えるChatGPTの画面。本家と比べると、会話のログが保存できないなどの制限があるが、お試しにはちょうどよい。筆者が用意した方(clone clone)は利用可能な限り最新のモデルが試せる。
図2. 無料で使えるChatGPTの画面。本家と比べると、会話のログが保存できないなどの制限があるが、お試しにはちょうどよい。筆者が用意した方(clone clone)は利用可能な限り最新のモデルが試せる。
 図3. 多義性を可視化するため広瀬友紀先生の挙げる「青い猫の傘」を出力させてみた。個人的なお気に入りは右上で、たしかに「青い猫の(形状をした)傘」と言える。
図3. 多義性を可視化するため広瀬友紀先生の挙げる「青い猫の傘」を出力させてみた。個人的なお気に入りは右上で、たしかに「青い猫の(形状をした)傘」と言える。
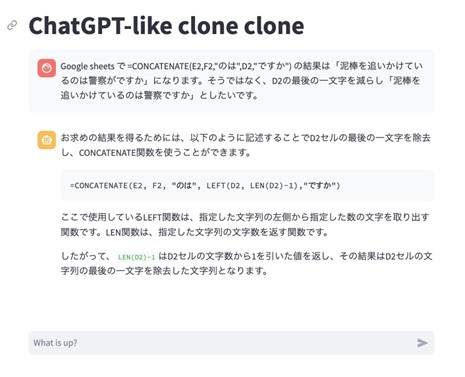 図4. Google Sheetsで所望の関数の使用方法を得る様子
図4. Google Sheetsで所望の関数の使用方法を得る様子
学生から「これって岸山先生ですよね」とYouTubeのショート動画(1)を見せてもらったことがある。後述するChatGPTの公開から約2か月後、テレビ東京の番組WBS(ワールドビジネスサテライト)で「AIを活用する英語講師」として取材を受けた。そのときの動画を見てうれしそうにする学生の表情に少しほっこりした。ただ、帰宅後にのぞいた関連動画を含めたコメント欄で複雑な気持ちになった。
というのも、コメント欄で筆者はボコボコに叩かれていた。「教員の風上にも置けない奴」、「自分の首絞めてるの分かってんのか」、「AIが出した宿題はAIに解かせて終わり」、「英語の講師なら英語でプロンプト(AIへの指示文)を書け」といった否定的なコメントばかりで見つけた唯一の肯定的なコメントはキーボード(2)に対してで泣きそうになった(図1)。
もちろん泣きそうになったというのは冗談だ。というのも、周りの先生に事前に打診した時に「AIの活用を問題視する人もいるだろう」と助言されていた。だから批判が特定の大学に向かないよう、取材時は実際の教材を使わずに所属も「都内の大学講師」と伏せた。しかし叩かれたとしても、高校で英語を教える筆者の姉を含め、多忙を極める教員へ活用事例を共有したかった。
前提の共有に失敗しているケースは議論ののびしろがないものの(3)、考えるべき論点もある。AIに問題を作らせることに教育的な懸念はないだろうか。あるいは学生の利用を禁じることは合理的だろうか。出力を批判的に吟味する、教育の目標や目的を意識する、著作権やコンプライアンス、個人情報の扱いを含めたガイドライン(4)に準拠する、こうした点を押さえておけば教員にしろ学生にしろ教育全般で試行錯誤して活用方法を探索するのは有益だと思う。
その他の論点として、英語講師・英語教育の需要はなくなるのだろうか。こちらは議論のスコープが広すぎて判断が難しい。ここでのエンジニア的常套手段はどちらに転んでも問題なくすることで、それがLinus Torvaldsの言う「よいテイスト」でもある(5)。条件分岐をなくせば意思決定の手順を減らせるし、動作確認や基準に悩む必要もなくなる。AIで英語講師が不要になるなら「AIで職を失う英語講師」の定義から外れればよく、英語教育自体が不要になるなら英語教育以外の付加価値を与えられる状態にすればよい。
そこで、今回はまずChatGPTを含めて大規模言語モデルに触れたことがない人向けに、どういう機能をAIが持つのかを確認してみよう。ChatGPTに登録するのが面倒な人向けに、登録せずに試せる環境を用意した。そして機能に将来性を感じた人向けに、ChatGPTをカスタマイズして使ったり、公開したりする方法を共有する。習うより慣れよ、これにつきる。
ChatGPT-like clone clone
まずChatGPTを試してみよう。筆者は抽象的な話の理解や説明が苦手なので、まずは手を動かしてもらいたい(6)。以下の話は2023年1月に受けた取材(7)をメインとした英語学習関連の話にくわえ、研究や開発で使うスクリプトを例としている。ただ、いずれも根底にあるのは「良し悪しを判断する」ことが前提にある。
説明のため、まずは以下のリンクからREADME.mdと呼ばれるファイルを参照してみてほしい(8)。ChatGPTを登録せずに利用できるアプリケーションへのリンクを紹介している。今回の前半ではこちらを使って説明を進めていくので、 "streamlit" を含むリンクを選択してほしい。つまり、下のリンクからさらにもう1つ別のリンクに飛ぶことになる(9)。
https://github.com/kishiyamat/chatgpt-like-clone-clone/blob/main/README.md
さて、最終的には図2のような画面に遷移すると思う。ページのトップにはChatGPT-like cloneやChatGPT-like clone cloneと書かれており(cloneは分岐したもの・同質なものを指す(10))、大切なのは一番下の“What is up?”と書かれた枠だ。右には紙飛行機マークもある。これが無料かつ登録なしでChatGPTを試す画面になる。つぎに使い方を説明する。
まずは試しに「モンゴルのホーミーとは?」などと記入して紙飛行機マークを押す。環境にもよるがShiftで改行ができるので、改行が必要な場合はうまく入力して空行を入れてほしい(つまり2回改行する)。すると、まるで誰かがタイピングしているかのように返事が返ってくる。
試すポイントは、自分が答えを知っていることを聞いてみるというもので、どの程度の知識を持っているかの温度感を得られる。なお「たぬき・むじな事件」は驚くほど毎回デタラメな結果になり、こうしたデタラメな(知らない人からすればもっともらしく聞こえる)嘘は「ハルシネーション(hallucination)」と呼ばれており、タスクの難易度に応じて可能性を考慮しなければならない。
注意点として、これは現状で最高に近い状態であるだけで今後も進歩し続ける点にある。決して今の状態だけを見て「はは、AIはこの程度か」と思い込んではならない。多くの資本(資金・人材・時間)が投資されている現状で、進歩がこれ以上ないという前提を筆者はまったく支持できない。大切なのは、現状の進歩に置いていかれないようにすることだ。
この点を筆者はさまざまなタイミングで学んできた。音声認識や翻訳が全く使い物にならなかった時代(間違いではないのだが「おおみそか」を”Oh, is it miso?”と訳していた時代)、画像生成ではガビガビのイラスト、あるいは線画をふわっと塗るのが精一杯だった時代もあった。でも今はどうだろうか。前者に関してはスピードを考慮しなくとも大多数のパフォーマンスを超え、後者に関してもDALL·E 3の画像は高品質で、意味の多義性(11)を視覚化するのにも便利だ(図3)。
変化するであろうものの、AIの現状の限界は確認できただろうか。先述した通り、たしかにChatGPTによる「たぬき・むじな事件」の解説は意味不明だし(Google Bardではまったく問題ない)、おそらく試したなかで同様の印象は受けたと思う。思ったより性能が高いと感じたかもしれないし、低いと感じたかもしれない。ただ少なくとも、意見の壁打ちや英語の授業、プログラミングに関してはいろいろと使える。
何と壁打ちをしているのか
個人的によく使うのは意見の壁打ちやアイデア出しだ。自分のあれこれ(ライフ・キャリアプランから研究の方向性、価値観の調整や書き物の構成や文体)をチェックしている。ただ、一体自分が壁打ちしている相手はどのような文字列をもっともらしいと評価しているのだろうか。これを見るのに筆者がよくテストに使っていたのは『この本の名は?』という書籍で紹介された問いだ。つぎの例は有名だが、ぜひ一緒に状況を整理しながら考えてみてほしい。
スミス氏とその息子アーサーが車で事故に遭った。父親は即死だったが、息子のアーサーは瀕死の重傷で病院に搬送された。病院で年配の外科医がアーサーを見た途端にこう言った。「手術は無理だ。これは息子のアーサーだから。」なぜ外科医は手術ができないのだろうか。
さて、もし上記の文章で「外科医=男性」で目の前にいるのが息子なら、「死んだはずの男性=父親」が生き返っていることになる。これをGPT-3の時代に試したところ、「自分の息子だから手術ができない」と返答された。筆者も高校生のころはまったく答えられなかった気がする。
だから書籍で「外科医がアーサーの母親だから」という解説をみたとき、自分のなかにないと思っていたジェンダーバイアスに気づいて驚いた。勝手に医者を男性と考えてしまっていたのだ。いや、ただ真っ先に女性を思い浮かべたら浮かべたで、それは女性へのバイアスを持っていることになってしまうが。
なんにせよ、GPT-4もこの正解とされる解釈にたどり着ける。でも、もう1つの解釈にはたどりつかない。というのも、「外科医がアーサーの父親だが、父親はすでに死亡している」という状態を矛盾と捉えるのは、「アーサーの両親は男性と女性のペアだ」という家族観のバイアスがのっているからだ。この解釈の場合、「アーサーは同性カップルの息子だから」が回答になる(12)。
したがって、これはすこし意地悪な問いだ。矛盾に思うならばジェンダーと結婚観のバイアスを発揮したことになる。外科医が母親と思うなら結婚観のバイアス、同性カップルの息子と思うならば職業のジェンダーバイアスを持っていることになる。ただ、結婚観のバイアスを持っている解釈を返せる程度の、もっともらしい文字列を生成する能力をAIが持っていることになる(13)。
念のためフォローすると、人によっては自分の中にあるバイアスやステレオタイプに気づいたときに不快感を抱いたかもしれない。もし不快感を与えてしまったら申し訳ないし、ACジャパンの「聞こえてきた声」に対する反応を見ても嫌がる人が多そうだ。ただ、バイアスを持っていること自体が悪いことだと思うのは生産的ではないので、もう1つだけ話を紹介させてほしい。
潜在連合テスト(IAT)という、一般に我々が他者に報告しようとはしないか、あるいは、報告することができない潜在的な態度や信念を測定できるテストがある。ジェンダーや人種といったスペクトラムと概念の結びつきの強さを測り、ステレオタイプを確認できる。例としてはハーバードのテスト(14)が利用可能なので試してみてほしい。筆者も自分の自動的な傾向を知って驚いたのを覚えている。
この点に対しては『心の中のブラインド・スポット』で述べられている通り、自分の中にある非意識のバイアスを把握して合理的な意思決定を邪魔しないようにするに限る。だから筆者も自分の中にあるバイアスを探すのが好きで、三軒茶屋のキャロットタワーにある男性用トイレに「化粧室」と書いてあって「いや男は化粧しないだろ」とふと思ったときもうれしくなった(15)。バイアスの存在自体に良いも悪いもなく、これは気づいて意識下に置ければ対応できるからだ(16)。
すくなくとも、現在利用可能なモデルは上記の「常識」をもっともらしいとしている。したがって、鵜呑みにさえせずに反論もはさめば十分に壁打ちやアイデア出しに使える。もう少し試したい場合、筆者が用意したモデルではソースコード(17)からわかる通り入力の記録はしていないので、悩みの相談でもしてみると雰囲気がつかめるかもしれない。
学習やプログラミングの効率化
それでは学習に関してはどうだろうか。批判的に読むことを想定した英文の作成、難易度や長さの調整、問題文や解説の作成などができる。誰を対象とした、どんな内容のテキストなのか、語彙のレベルなどの指定も現実的に利用できる水準で動く。ただ、学生の反応を観察して思うのはやはり議論させることには2つの側面から利用価値がある。
議論が使いやすい理由の1つは、そもそもAIの主張の真偽が問題にならないからだ。真偽が問題になるのは情報が偽であり利用者が鵜呑みにしてしまう状態であるが、議論においては鵜呑みにはせず批判的に考える。AIを批判し、AIに批判されることで思考を深く掘っていける。これは感情的にならず疲れ知らずのAIだからこそ実現できる。
もう1つの理由は、学習者を含めて人はAIから批判されることを恐れないからだ。これはDuolingoのような発音学習にしろGrammarlyのような文法チェッカーにしろ、AIによる評価を怖がる人を筆者はみたことがないし、1人の学習者としても怖がる理由がない。もちろん表現の言い回しの修正などは真偽がわからないので教員の補助が必要だが、あきらかな指摘のミスよりも有用な指摘も多く、むしろ教員にとっても学生へのAIのフィードバックが勉強になることが多い。
では、一体どの程度が現状で対応できるのだろうか。個人的に好きな書籍の『実は知らない英文誤読の真相88』に出てくる問題をスラスラと正答でき、仮に誤答したとしてもいずれは解消されるように思える。ChatGPTでは音声の入出力や画像の生成もサポートされ始め、今後もあらゆる場面で使えそうだ。ただ、より高度なテキストでは疑問が残る解釈もあるので、やはり全面的に人の対応が不要になるのはまだ先になる。
ちなみに、実際に使ってみて「もう英語勉強しなくていいじゃん」や「もう英語の先生いらないじゃん」と感じただろうか。少なくとも、英語でも出力する身としてはどのみちAIによる出力の正誤判定ができる程度の能力は必要だし(18)、学習者ならば出力結果が正しいか分からないので人のサポートが必要と感じた。ただ、大きく従来を変えるポテンシャルは感じる。この点はTom Gally先生も指摘しているので関連動画を確認してみてほしい(19)。
もう1点だけ使い方を紹介すると、それはIT周りだ。身近なものとしてはGoogle Sheetsが挙がるかもしれないし、PythonやRといったプログラミングでの活用もできる。こうした分野で使いやすい理由としては、期待する動作が定まっている場合が多いということにある。それぞれの例をみていこう。
まずGoogle Sheetsで、「警察が 泥棒を 追いかけている 犬を 見ていた」という5つの単語が5列に格納されているようなケースを考える。ここから疑問文を入れ替えて作りたいとき、助詞をわけていなかったので単純な入れ替えと文字の挿入では「泥棒を 追いかけている のは 警察が ですか」となってしまう。「警察が」えはなく「警察」と最後の1文字を減らせれば、所望の文字列になる。これをChatGPTに指摘すると(図4)、所望の関数を得られる。
他にもRやPythonでも同じだ。期待する動作を述べればコードを生成してくれる。個人的に推したい事としては、利用するライブラリの指定である。つまり、Rで言えばtidyverseとggplot2を利用する事、Pythonで言えばpandasやplotnineを利用することを指定する。そのほかにも、テーブルはマークダウン形式で扱うと便利といった細かいTipsはあるが、そこら辺は巷に溢れているのでここでは省く。
以上のように、AIが出力するもっともらしさ(あるいは「常識」)や利用方法について簡単ではあるが述べてきた。再度になるが、これは実際に触っていろいろと試してみるのが早い。文章校正といったものでも構わない。筆者の用意したものは特に制限を予定していないが、もしもっと使ってみたいと思う場合は登録して使い始めるのをお勧めする。また、課金の必要性は実際に課金している人の話を聞いてみるとよいだろう。
こうした機能をほかの人に使ってもらいたいと思うのは自然な感覚に思える。すべての人が自由にツールを公開して自分で使ったり、ほかの人にカスタマイズした機能を使ってもらったりすれば、業務を効率化できるだけでなく、これまで実現できなかった環境が待っている。最後に、機能に将来性を感じた人向けに、ChatGPTをカスタマイズして使ったり、公開したりする方法を共有する。
参考文献
佐藤, ヒロシ. (2009). 実は知らない英文誤読の真相88. プレイス.
スマリヤン, レイモンド. M. (2013). この本の名は? 嘘つきと正直者をめぐる不思議な論理パズル (川辺治之, 訳.). 日本評論社.
バナージ, マハザリン. R., & グリーンワルド, アンソニー. G. (2015). 心の中のブラインド・スポット: 善良な人々に潜む非意識のバイアス (北村英哉 & 小林知博, 訳.). 北大路書房.
(1) https://www.youtube.com/shorts/ZdDqy65a790
(2) https://happyhackingkb.com/jp/products/discontinued/hhkb_protypes/
(3) プロンプトを日本語で書いた理由は番組の視聴者が誰かを考えれば察せると思うし、AIに問題を解かせることは論外だ。感情的な主張はアルゴリズム嫌悪によるものなのだろうか。
(4) https://utelecon.adm.u-tokyo.ac.jp/docs/ai-tools-in-classes
(5) https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux
(6) 「例示は理解の試金石」という表現もあるので具象を重んじるのは理解に貢献する気もする。
(7) https://txbiz.tv-tokyo.co.jp/wbs/vod/267482
(8) READMEというのはよく開発周りで使う表現だ。アプリケーションをダウンロードしたときにREADME(つまりread me、「私を読んで」)と呼ばれるファイルを最初に開く。これはアリスの世界にあるeat meと書いてあるクッキーと同じだ。
(9) 仕様の変更などでURLが変わるリスクを避けるため、一度特定のサイトを経由した。
(10) https://www.mext.go.jp/b_menu/shingi/kagaku/klon98
(11) https://www2.ninjal.ac.jp/past-events/2009_2021/event/specialists/project-meeting/m-2020/20201016/
(12) 『マチルダとふたりのパパ』という絵本があるが、どのような家族構成を想像するだろうか。
(13) この指摘をした時の回答は「すみません、おっしゃる通りです。その答えももちろん正しい可能性があります。その外科医はアーサーのもう一人の父親である可能性があります。どちらが正解であるかは、問いの文脈や背景によるところが大きいです。私の回答は常識的な解釈に基づいていましたが、あなたの解釈は多様性を重視した視点を示しており、重要な指摘をありがとうこざいます。」だった。常識を問われると筆者は弱い。
(14) https://implicit.harvard.edu/implicit/japan/
(15) それを言ったらbathroomはどうなるんだとも思うが。
(16) 「バイアスを持っていることが悪」という認識で問題になるのは、そうすると人は「自分はバイアスを持っていない」という立場をとることにある。議論が他人事になるし、バイアスを意識することがなくなってしまう。
(17) https://github.com/kishiyamat/chatgpt-like-clone-clone/blob/main/app.py
(18) 英語を完璧に日本語にしたところで、その「日本語なら理解できる」という自信の源が疑問だが、学ぶ・理解する姿勢を放棄するリスクも考慮して意思決定したい。
(19) https://www.youtube.com/watch?v=l41hZLRsDos
-
- 2023年11月28日 『8. 言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議:読みづらい文・誤解する文 岸山健(法政大学文学部英文学科ほか非常勤講師)』
-
読みづらい文・誤解する文
 図1. インターネットの界隈でバズったツイート。浅瀬蟲というカードを後輩が買ったらしい。
図1. インターネットの界隈でバズったツイート。浅瀬蟲というカードを後輩が買ったらしい。
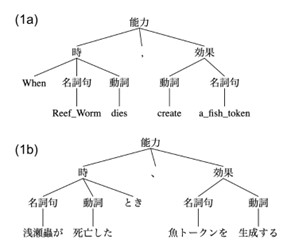 図2. 英語文“When Reef Worm dies, create a Fish token” と 日本語文「浅瀬蟲が死亡したとき、魚トークンを生成する」に筆者が与えた構造
図2. 英語文“When Reef Worm dies, create a Fish token” と 日本語文「浅瀬蟲が死亡したとき、魚トークンを生成する」に筆者が与えた構造
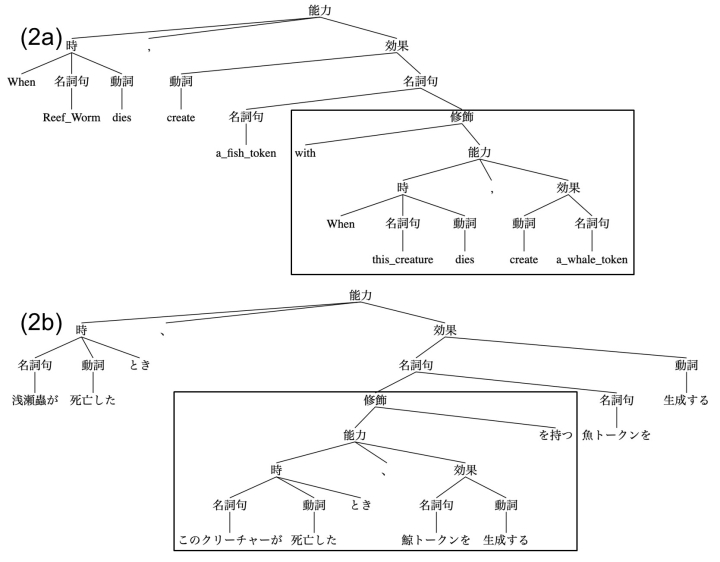 図3. 英語文“When Reef Worm dies, create a fish token with “When” this creature dies, create a whale token” と 日本語文「浅瀬蟲が死亡したとき、「このクリーチャーが死亡したとき、鯨トークンを生成する」を持つ魚トークンを生成する」に筆者が与えた構造
図3. 英語文“When Reef Worm dies, create a fish token with “When” this creature dies, create a whale token” と 日本語文「浅瀬蟲が死亡したとき、「このクリーチャーが死亡したとき、鯨トークンを生成する」を持つ魚トークンを生成する」に筆者が与えた構造
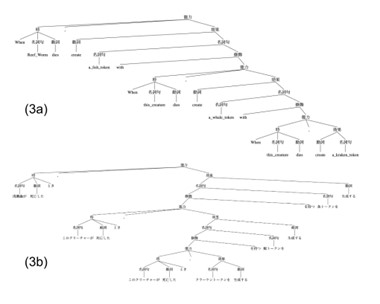 図4. 例文(3ab)に与える構造。英語の(3a)と日本語の(3b)で形が異なる。カードの和訳としては読みづらいが、原文が持つ再帰的な構造を保存した綺麗なケースに感じた。
図4. 例文(3ab)に与える構造。英語の(3a)と日本語の(3b)で形が異なる。カードの和訳としては読みづらいが、原文が持つ再帰的な構造を保存した綺麗なケースに感じた。
誰しも人に話したくなるような奇妙な経験を持っていると思う。たとえば、たまたま乗った電車でばったり、かつて親しくしていた友人に出くわすような、偶然に偶然をかけあわせたような出来事だ。以下に共有する話は、偶然を少なめに見積もっても3回はかけあわせたもので、しかも言語や情報処理への示唆を含むので、ぜひとも共有したい。
ここまで単語や音の話をしてきたが、対象をがらりと変える。今回のメインの話は、人間の言語の構造と、言語に構造を与える処理についてだ。読みやすい文を書くコツや、言語学者と呼ばれる人々の一部が言語の構造や処理を見続けられる理由を、変わった形で共有する。まずは軽めの導入として、ネットの一部界隈で話題になった投稿から紹介しよう。
カードの翻訳と読みづらさ
本人の許可を得たので、その投稿の画像を図1に引用する(1)。本文に関係する情報を整理すると、大まかには上から (a) 投稿者情報(トロピ大塚さん)と(b) 短文、(c) 画像欄の3つに分けられる。画像の下には、投稿時刻や表示回数、リポスト・いいねの数などが示されているが、今回のメインは (c)にしめす画像欄だ。画像欄で共有されている左右2枚のイラストの下には、日本語と英語の文章が示されている。
この投稿で偶然がどのようにかけあわされているのかは最後に共有するとして、言語に興味を持っている人の心をつかむのは、左右で日英対照される「中央に埋め込まれた」テキストだ。このテキストを説明するためには、まず世界的に人気を集めるトレーディングカードゲーム「マジック:ザ・ギャザリング」(以下、MTG)の説明が必要だ。
MTGはカードを使った対戦ゲームであり、プレイヤーは「プレインズウォーカー(Planeswalker(2))」という魔法使いを演じる。プレイヤーは各自が所有するカードの束(=デッキ)からカードを引き、魔法の呪文を唱えたり、「クリーチャー」を戦場に召喚したりして戦い、相手ライフポイントをゼロにして勝利を目指す。図1で引用した投稿が示すカードは、《浅瀬蟲》というクリーチャーを戦場に出せる。
さて、この《浅瀬蟲》は効果(アビリティ)を持っている。基本的にクリーチャーは攻撃や防御を行うためのカードだが、多くのクリーチャーには追加の効果が付随する。これらの効果は、クリーチャーが持つ特性や能力を示し、ゲームの戦略的な深みを与える。クリーチャーの効果には、常に効果が適用される静的なものや、特定の事象に誘発されるものなどがある。
ここで話題にあげた《浅瀬蟲》の効果を読んで(あるいは眺めて)みよう。
浅瀬蟲が死亡したとき、「このクリーチャーが死亡したとき、『このクリーチャーが死亡したとき、青の9/9のクラーケン・クリーチャー・トークン1体を生成する。』を持つ青の6/6の鯨・クリーチャー・トークン1体を生成する。」を持つ青の3/3の魚・クリーチャー・トークン1体を生成する。
もちろん、「トークン」や9/9や6/6という表記を知らないと全ては理解できない。トークンとは、カードとしてデッキに含まれるのではなく、特定の効果によってゲーム中に生成されるクリーチャーの代用品である。物理的なカードである必要はなく、コインや紙片などで代用することができる(3)。また、9/9や6/6はクリーチャーの能力で、攻撃/守備の形式を取る。ただ、この説明を追加しても、上の文は読みづらいだろう。
大塚さんの解説によると、以下の効果と言えるらしい。
この『浅瀬蟲』が死亡して墓地に置かれると、3/3の魚クリーチャー・トークンが場に出現します。そしてこの魚が死亡すると、次は6/6の鯨クリーチャー・トークンが場に出現します。そして鯨が死亡すると、最後に9/9のクラーケン・クリーチャー・トークンが出現する…という能力になっています。
これならわかりそうだ。筆者はMTG未経験者だが、死ぬと強くなって親分が出てくるイメージだ。でも、このテキストの理解が難しかったのは、MTGのルールを知らないからだろうか。それとも、言語の構造として理解し難いのだろうか。これを確認するために、似た構造を持つ、我々の知っている単語を持つ文を見てみよう。
僕は家に帰ったとき、「遊びに来るとき、『人の家に寄るとき、両親を呼ぶ』恋人を呼ぶ」友人を呼ぶ。
よし、理解できない。シチュエーションの意味が不明なのだろうか。理解度確認テストとしては「誰の恋人が呼ばれますか?」という問いでよいだろう。友人と「僕」のどちらの恋人だろうか(4)。分かりやすさのため、大塚さんのように以下のように言い換えてみよう。
僕は家に帰ったとき、友人を呼びます。その友人は遊びに来たとき、恋人を呼びます。その恋人は人の家に寄るとき、両親を呼びます。
こう書くと、はた迷惑な効果を持つ友人だということがわかる(その効果を持っているのは「僕」なのでお互い様だが)。ただ、現実に起こりうるかはさておき、さきほどに比べればずいぶんと理解しやすくなった。つまり、友人を呼ぶと、連鎖的に友人の恋人と、恋人の両親まで召喚することになる。したがって、もとの文の読みづらさは語彙に起因しないことがわかる。
では上の2つの文の読みづらさは何に起因するのだろうか。ここで《浅瀬蟲》の英文を見てみる。同じように読みづらいのだろうか。
When Reef Worm dies, create a 3/3 blue Fish creature token with "When this creature dies, create a 6/6 blue Whale creature token with ‘When this creature dies, create a 9/9 blue Kraken creature token.'"
こちらの文は下に示す通り、大塚さんの説明とほとんど同じでむしろ読みやすい。補足する点があるとすれば、「名詞 with 能力」という形で、その名詞がwith以下のもの(ここでは効果)を持つことを示せるところだろうか(5)。
When Reef Worm dies, create a 3/3 blue Fish creature token: この『浅瀬蟲』が死亡して墓地に置かれると、3/3の魚クリーチャー・トークンが場に出現します。
with "When this creature dies, create a 6/6 blue Whale creature token: そしてこの魚が死亡すると、次は6/6の鯨クリーチャー・トークンが場に出現します。
with ‘When this creature dies, create a 9/9 blue Kraken creature token.'": そして鯨が死亡すると、最後に9/9のクラーケン・クリーチャー・トークンが出現する…という能力になっています。
同じ能力を述べているのに、ほとんど同じ単語を使っているのに、どうしてこうも理解のしやすさに差が生まれるのだろうか。そこで考えたいのが言語の構造だ。
言語の文法と構造
この読みづらさを考えるために、そして「言語の構造」が示す対象を早めに共有するために、英語と日本語の構造を見比べていこう。まず考えたいのは以下の英語文(1a)と日本語文(1b)で、これは浅瀬蟲の効果を考える上で最もシンプルな文になっている。
(1)
a. When Reef Worm dies, create a Fish token
b. 浅瀬蟲が死亡したとき、魚トークンを生成する
図2の(1a)と(1b)には、それぞれに対する構造を与えてある。いかつい図だが、各構造の一番下には単語の層がある。そして一番上をみると、能力が「時+読点(、)+効果」から構成されることを示している。
なお、これらの図は後に複雑になっていくが、ノートブック上で確認・動作できる。
https://github.com/kishiyamat/la-kentei-yaminabe/blob/main/notebooks/mtg.ipynb
文(1a, b)に与えた構造に違いがあるとすれば、効果をトリガーする「時」の内部が、英語では「When 名詞句 動詞」であるのに対し、日本語では「名詞句 動詞 とき」であることだろうか。また、「効果」の内部も英語では「動詞 名詞句」であるのに対し、日本語では「名詞句 動詞」と入れ替わっている。この時点ではまだ読めるが、問題は魚トークンが効果を持っていることを説明する際の違いにある。
日本語と英語の構造の間にある違いの1つは、上に示したようなパーツの前後だろう。「効果」を述べる時、英語では動詞が前にくるのに日本語では後ろに来る。「時」を述べるとき、英語では When が前に来るのに日本語では後ろにくる。さらに、名詞句を修飾する方法も異なる。つぎに、1つ複雑にした文(2a, b)を見てみよう。
(2)
a. When Reef Worm dies, create a Fish token with “When this creature dies, create a Whale token”
b. 浅瀬蟲が死亡したとき、「このクリーチャーが死亡したとき、鯨トークンを生成する」を持つ魚トークンを生成する
これらの文は、まだ耐えられるはずだ。それぞれの構造を図3の(2a)と(2b)に示す(6)。さきほどと比べて様子が違い、英語は右下に修飾表現がつけくわえられたのに対し、日本語では木が中央に埋め込まれている。ただ、背景にあるのは順序の違いで、名詞句を足すとき、英語では主要な要素である名詞を前に、日本語では後ろに置く。
これらの違いを平たく言うと、大事なものを先に置くか後ろに置くかという違いに単純化できる。図3の(2a)と(2b)をもう少し眺めてみよう。まず(2b)「時」の中の「とき」を英語のようにさきにおくと、(2a)と同じ順序になる。効果の名詞句と動詞、名詞句の修飾と名詞句をひっくり返す。それを四角の中の「時」、「効果」、「名詞句」で繰り返せば、英語とおなじ順序になる(7)。
英語と日本語という別々の言語なのに、この「大切な要素を前に置くか後ろに置くか」というパラメータをスイッチするだけで、それぞれの単語は違うが同じ構造を生成できるのにはやっぱりロマンがある。今回見たものはシンプルすぎる、特殊なMTGというゲーム内の文法だが、これが我々の使う自然言語でもできるならアツい展開だ。
構造と読みづらさ
さて、読みづらい文の話に戻ろう。図3の「鯨トークン」を修飾する要素はどこに挿入されるだろうか。英語なら、修飾は名詞句の後ろに配置されるが、日本語では前に配置される。だから、さらに中央の埋め込みが日本語では深くなってしまう。さらに修飾表現を足した文を(3a, b)に見てみよう。
(3)
a. When Reef Worm dies, create a Fish token with “When this creature dies, create a Whale token with ‘When this creature dies, create a Kraken token’”
b. 浅瀬蟲が死亡したとき、「このクリーチャーが死亡したとき、『このクリーチャーが死亡したとき 、クラーケントークンを生成する』を持つ鯨トークンを生成する」を持つ魚トークンを生成する
さきほどの(2b)では辛うじて理解できていた日本語文だったが、これで少なくとも言語学を専攻しておらず説明を受けていない状態では理解できなくなった。見えることは期待しないが、形だけでも共有する意味はあるので対応する構造を図4に示す。
前回紹介した書籍『言語という名の本能』には、困った文が3つ紹介されている。これらは玉ねぎ文、ガーデンパス文、構造的多義文と言える(8)。ガーデンパスや構造的な多義性はとっておくとして、上の浅瀬蟲の日本語版はこの「玉ねぎ文」に相当し、再帰的な構造を持っている。
読みづらい理由としては、「能力」の説明が終わらないうちに別の「能力」の説明が始まり、そしてその「能力」の説明が終わらないうちに…と文が入力されることで、未完の「能力」の処理が積みあがってしまうことにある。これが日本語に限らず英語でも、処理しづらい文になる。ほかにも例を見てみよう。
以下の(4a-c)は『言語の数理』(長尾ほか, 2004)からの引用であり、(4a)は左下に構造が伸び、(4b)は右下に構造が伸びるケースだ。そして(4c)が中央埋め込みで、これもさらに伸ばしていくと理解が難しくなる。それに対して、(4a)も(4b)も埋め込まずに伸ばす限りは文の理解を妨げない。
(4)
a. 私の弟の友人
b. 今日やっとひとつ荷物が届く
c. 明日あのさっき君を助けた人が来る
もし、未完の構造を何個も維持するのが理解の妨げになるというのなら、未完の構造を作らなければよい。たとえばだが、「…とき」を3つすべて動詞の直前に再配置してたらどうなるだろうか。まず(5a)に再掲した文を、(5b)、(5c)と変えていく。
(5)
a. 浅瀬蟲が死亡したとき、「このクリーチャーが死亡したとき、『このクリーチャーが死亡したとき 、クラーケントークンを 生成する』を持つ鯨トークンを生成する」を持つ魚トークンを生成する
b. 「このクリーチャーが死亡したとき、『このクリーチャーが死亡したとき 、クラーケントークンを 生成する』を持つ鯨トークンを生成する」を持つ魚トークンを浅瀬蟲が死亡したとき生成する
c. 「『このクリーチャーが死亡したとき、クラーケントークンを 生成する』を持つ鯨トークンをこのクリーチャーが死亡したとき生成する」を持つ魚トークンを浅瀬蟲が死亡したとき生成する
あるいは、両親を召喚する恋人を召喚する友人を召喚する例はどうだろうか。
(6)
a. 僕は家に帰ったとき、「遊びに来るとき、『人の家に寄るとき、両親を呼ぶ』恋人を呼ぶ」友人を呼ぶ
b. 「『人の家に寄るとき両親を呼ぶ』恋人を遊びに来るとき呼ぶ」友人を僕は家に帰ったとき呼ぶ
どちらも悪文であることに違いはないにせよ、全く理解できないわけではないと思う。すくなくとも、「誰の恋人が呼ばれますか?」という理解度確認テストの正答率はあがるだろう(9)。処理の途中で別の処理を挟ませない、これが玉ねぎ文の生成を避ける方針に思える。
実はこの《浅瀬蟲》、たまたま大学院仲間から聞いて「こんな面白いカードがあるのか!」と思わず筆者も買ってしまった。届くや否や、同じく言語学を学んだ別の友人へメッセージを送ったのだが、偶然にもその方のパートナーがMTGに詳しかった。そしてその方が短文をネットに投稿をしたところ思いかけず話題になり、最初に《浅瀬蟲》を教えてくれた大学院仲間のタイムラインに現れて、「あれ、これ岸山のことじゃ…」となったらしい。そして見せてくれたのが図1だった。すごい偶然だ。
さて、これを玉ねぎ文にするにはどうすればよいだろうか。まずは情報を整理しよう。
1. 大学院仲間が面白いカードを岸山に見せた
2. 岸山はそのカードを大学時代の友人に伝えた
3. 大学時代の友人はパートナーに共有した
4. そのパートナーはツイートを投稿した
5. 大学院仲間が図1のツイートを岸山に共有した
これを内側に埋め込めばいい。上の5から徐々に微修正しながら中央に埋め込んでいく。
(7)
a. 大学院仲間が図1のツイートを岸山に共有した
b. そのパートナーは「大学院仲間が岸山に共有した」図1のツイートを投稿した
c. 大学時代の友人は『「大学院仲間が岸山に共有した」図1のツイートを投稿した』パートナーに共有した
d. 岸山はそのカードを<『「大学院仲間が岸山に共有した」図1のツイートを投稿した』パートナーに共有した>大学時代の友人に伝えた
e. 大学院仲間は【岸山が<『「大学院仲間が岸山に共有した」図1のツイートを投稿した』パートナーに共有した>大学時代の友人に伝えた】面白いカードを岸山に見せた
このおぞましい中央埋め込み文(7e)を解消すると(8)になる。
(8)
a. 【<『「大学院仲間が岸山に共有した」図1のツイートを投稿した』パートナーに共有した>大学時代の友人に岸山が伝えた】面白いカードを大学院仲間は岸山に見せた
b. 大学院仲間が岸山に共有した図1のツイートを投稿したパートナーに共有した大学時代の友人に岸山が伝えた面白いカードを大学院仲間は岸山に見せた
正直(8a, b)も「文を分けましょう」と言いたくなるが、(7e)の致命的な分かりづらさに比べれば努力次第で読める。努力しないと読めない時点で読み手のことを考えた文とは言い難いが、人間が文を理解する過程がこの違いから垣間見えるのはやはり面白いし、言語の奥にある構造を眺めるのは専門じゃない筆者としても楽しい。
いつの日か、見つけた玉ねぎ文を刻んでほかの人が食べやすいよう調理してみてほしい。
参考文献
長尾, 真., 中川, 裕志., 松本, 裕治., 橋田, 浩一., & ベイトマン, ジョン. (2004). 岩波講座言語の科学: 言語の数理. 岩波書店.
Pinker, S. (1995). 言語を生み出す本能[上] (直子. 椋田, 訳.). 日本放送出版協会.
(1) https://sirabee.com/2023/02/21/20163028339/
(2) MTGのストーリーは、久遠の闇と呼ばれる広大な空間に無数の次元(プレイン)が存在する多元宇宙を舞台としており、プレインズウォーカーは次元(プレインズ)を渡り歩く存在である。
(3) なお、浅瀬蟲関連のトークンはカードになっている。
(4) もし「僕は「恋人を呼ぶ」友人を呼ぶ。」という文があったとき、誰の恋人だろうか。その答えと一致するはずである。
(5) A man with a telescope. は「望遠鏡を持った男」と訳せる。
(6) こちらも見づらい場合は上記のノートブックのURLを参照してみてほしい。
(7) つまり、「とき 浅瀬蟲が 死亡した、生成する 魚トークンを を持つ(=with)「とき このクリーチャーが 死亡した、生成する 鯨トークンを」」になる。
(8) onion (or Russian doll) sentences, garden-path sentences, ambiguous sentences
(9) もし「「恋人を呼ぶ」友人を僕は呼ぶ。」という文があったとき、誰の恋人だろうか。その答えと一致するはずである。
-
- 2023年10月24日 『3. 言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議:魔法世界の裏側は博物館? 岸山健(法政大学文学部英文学科ほか非常勤講師)』
-
魔法世界の裏側は博物館?
 図1. 現在も、筆者が小学生だったころの三軒茶屋駅のホームの雰囲気もすこし残っている。
図1. 現在も、筆者が小学生だったころの三軒茶屋駅のホームの雰囲気もすこし残っている。
 図2. 渋滞する世界観にたたずむ守護霊
図2. 渋滞する世界観にたたずむ守護霊
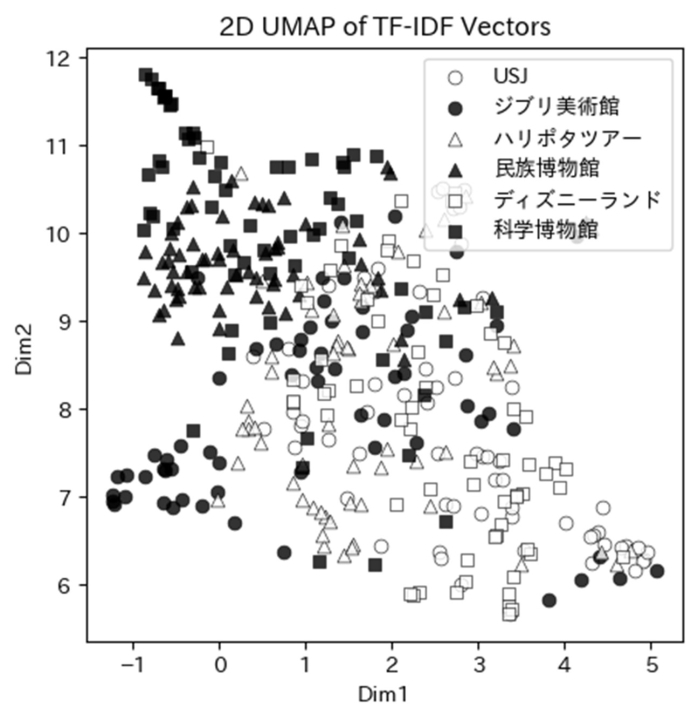 図3. 各文書を5000次元から2次元に変換してプロットした図。この結果は手順の初期値に依存するため安定しないことに注意したい。
図3. 各文書を5000次元から2次元に変換してプロットした図。この結果は手順の初期値に依存するため安定しないことに注意したい。
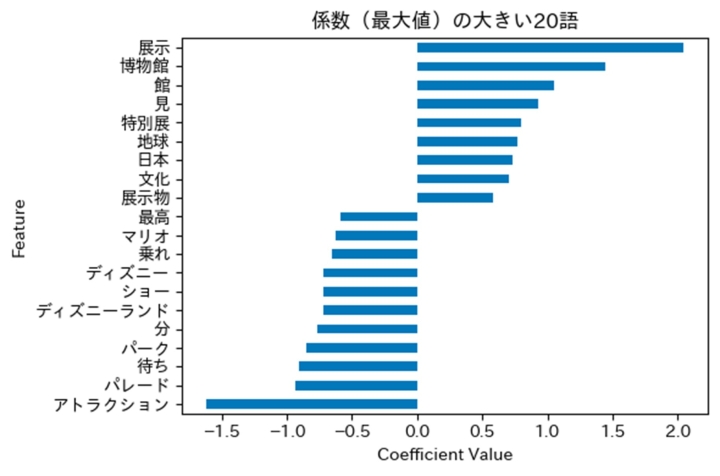 図4. 各単語のTF-IDF値に対する係数を示す。
図4. 各単語のTF-IDF値に対する係数を示す。
小学生のころに『ハリーポッターと賢者の石』の映画や物販に連れて行ってもらった記憶がある。あの世界観には不思議な現実感があって、9と4分の3番線も世界のどこかにあるんじゃないかと期待していた。なんなら当時、世田谷線の三軒茶屋駅のホームがレンガ造りで雰囲気が似ていて(図1)、壁に突っ込みたくなったこともある。突っ込まなかったことから考えると、小学生のころのほうがまだ自制心があったのかもしれない。
あの魔法の世界に現実感を与えた技術の裏側は、としまえんの跡地にできた施設「スタジオツアー東京」で見ることができる。ハリーポッターの映画を作成する過程を紹介しており、教育的側面とエンターテイメントのさじ加減が絶妙だ。
そんなスタジオツアー東京(以下、ハリポタツアー)、すこしばかりオープン前に議論を呼んだことがある。なにしろとしまえんという遊園地の跡地に建てられる施設だから、遊園地的な性質を持っているのではと考える人も多かった。公式の紹介文でも「エンターテイメント施設」と明言しているので(1)、いかにもディズニーランドのハリーポッター版を想像したくなる。でも、仮にそうだとすると問題になることが前から指摘されていた。
そこで、懸念されていた問題の概要と、実際に筆者が行って感銘を受けた点を共有した後で、「単語の分布で文書を表現・比較する方法」を見ていきたい。きっと多くの言葉に興味を持つ人にとっては新しい話題だし、言葉を数字で扱うと何がうれしいのか、すこしだけ共有できると信じている。
ハリポタツアーで懸念されていた問題には、としまえん跡地が「第二種住居地域」という「用途地域」に該当する点が関係する。用途地域では、何を建ててOKか・NGかが建築基準法で定められている。そして第二種住居地域のNGリストには、劇場や映画館、演芸場、展示場、遊技場が含まれる。ハリポタツアーは「博物館その他これに類する施設」とされているが、としまえんという遊園地の跡地にできる「エンターテイメント施設」がNGリストに該当しないのか、という懸念があった(2)。実際、ハリポタツアーの話をまだ行ってない学生が「開館」ではなく「開園」と表現しているのは耳にしたことがあるし、結構話題になっていた(3)。
この点に関して友人の一級建築士に質問したところ、施設が作られる際は周辺調査業務→依頼→設計→申請→申請許可→着工という段階を踏むところから説明してくれた。この「遊戯場か博物館か」という点は、設計のタイミングで役所に確認するが、もちろん用途地域に適していない遊戯場では通らない。これは施主にも明らかであるため、博物館の用途で申請する施設を建てることを事前に市役所と確認するそうだ。法律は多角的なとらえ方が出来るため、適合する解釈を役所と調整していくことになる。
ほかにも博物館法(4)において芸術や産業の資料の収集や保管、展示を「博物館」の定義に使っているので、映画という芸術・産業の資料の展示を前提として認められたのではないかとも話してくれた。こう言われてみると確かに博物館かもしれない。ただ、言葉として「開園」とか「エンターテイメント施設」と共起、つまり共に使われる概念が「博物館その他これに類する施設」と言われるのは、僕の言葉に対する感覚がもぞもぞした。ということで、予約サイトのチケット争奪戦に勝利し(1勝8敗)、実際に見学してみた。
当日、大江戸線の豊島園駅を降りて、7月の照りつける太陽を日傘で遮りながら、人の流れについていった。やはり第二種住居地域というだけあり、閑静な住宅街とまではいかないが、魔法使いのテーマパークがあるとは全く思えない。標識やベンチなどに残るとしまえんの面影を懐かしみながら歩いていくと、西武豊島線の開けた駅前に着いた。
そこはスタジオツアー東京の入り口に近い場所なのだが、北京料理とシアトル系喫茶を背景に鹿の守護霊がいて世界観が渋滞気味だった。こういうのも形容矛盾っぽくて趣深いが、日差しに耐えられないので写真を1枚とって進む(図2)。敷地内に入っても途中まではチケットは不要だから、魔法世界に関連したオブジェを眺める広場になっていて散歩している人も見える。
入館した第一印象は、思わず「入館」という動詞を使ってしまったことから察せるように「美術館や博物館に近いかもしれない」というものだった。館内左手にはショップがあり、右手ではツアーガイドの受付をしている。すこし早く着いたのでショップを回ってみても、作品に思い入れのある人なら思わず手に取ってしまうものばかりで、危うくツアーをすっぽかすところだった。
参加したツアーの冒頭も声優が挨拶する映像だ。概要としては、ツアーで映画制作の技巧を楽しんでほしいということだった。考えてみれば、この場で声優の顔を初めて見る人もいただろう。魔法の世界は当然フィクションだが、映画自体は現実の人間が作っている。単に映画の世界を体験できる施設だと思って来た人も、改めて気づいた事実にワクワクするのではないだろうか。
ツアーの内容に関して触れると未見の人のよろこびを奪ってしまいかねないので無難な範囲で述べると、映画にある架空の世界が現実から生まれる過程を学んだ。魔法使いが持つ杖の形には意図があり、劇中の大男が住む小屋の脇にある鉢が倒れているのもきっと同じだ。その意図を見せてくれるから、何かを作ることに関わる人間ならば必ず楽しめると思う。
総じて、非常に教育的価値の高い施設だった。映画をみるときに新しい観点を与えてくれるし、きっとほかのドラマやアニメの解釈にも「この食器は登場人物の性格を反映して選ばれたんだな」といった奥行きを与えてくれる。もちろん意味なんてないかもしれないが、消費者としての解像度は間違いなく上がる。少なくとも人の努力にまた1つ気づけるようになったので、それはよろこばしい。
結局、個人的には「博物館」といってまったく違和感を覚えないどころか、博物館にエンタメの要素をうまく混ぜ込んで収益性を確保した企画に脱帽する。でも話はもうすこしだけ続く。つぎにしたいのは言語の話で、人が持った印象や感想を分析して「これは博物館だ」という直感はサポートできるのだろうか。でも、出口で待ってほかの来場者に感想を聞くのも変だ。せっかく実りの多い一日だったのに、最後に挙動不審なメガネに「ア、アノ、フフ、チョットイイデスカ」など声をかけられたのでは台無しだ。大人しくデータを活用しよう。
TF-IDFとロジスティック回帰
さて、人々が持つ感想としてもハリポタツアーは「博物館その他これに類する施設」なのだろうか。この問いを考えるために、感想を数字で表す工夫をしてみよう(5)。
https://github.com/kishiyamat/la-kentei-yaminabe/blob/main/notebooks/haripota_museum.ipynb
まずはGoogle Mapsのレビューを眺めて、ハリポタツアーの感想を数十件得た(6)。博物館の例として思い浮かんだのは国立科学博物館や国立民族学博物館、属さない施設の例としては東京ディズニーランドやユニバーサルスタジオジャパン(USJ)がある。美術館などとの中間として思い浮かんだ例には「三鷹の森ジブリ美術館」がある。これらの施設で合計数百件の感想を均等に収集した。
つぎに感想を数字に置き換えるため、「TF-IDF」という表現を紹介したい。このTF-IDFを使うと、文書(ここでは感想)を語彙数の数字で表現できる。もし頻度の高い5000語まで考慮するなら、1つの文書は5000個の数字に置き換えて表現できる。前回は画像を1024個の数字で表現したが、今回は文書を5000個の数字で表現することになる。
ある文書XをTF-IDFに変換する際、まずは5000語のそれぞれで「TF」と「IDF」を計算していく。TF(Term Frequency)は、「この単語は、文書Xの中で何回出てきたか」を数える。もし「展示」が3回出てきたら3になる。IDF(Inverse Document Frequency)は、頻度の逆数なので「が」のような(他の文書も含めて)頻度が高い単語は逆に小さい値をとる。頻度の低い単語では高い値になる。
つまり、TF-IDFとは文書ごとに各単語で「この文書の中に何回出てきたか(TF)」を「この単語はどれくらい珍しいか(IDF)」で重みづけた値になる(表1)。
表1. 架空のデータでTF-IDFの求め方を説明する。マスはTF*IDFとしており、ここではIDFの代わりに値の大きさを大中小で示している。「が」や「楽しい」のような頻出語は数値による表現で貢献する度合いが小さい。楽しい 長い 展示 行列 映画 … が 楽しい 展示 が... 1*小 0*中 1*大 0*中 0*大 … 1*小 映画 が... 0*小 0*中 0*大 0*中 1*大 1*小 長い 行列 が... 0*小 1*中 0*大 1*中 0*大 1*小
これで文書(感想)をTF-IDFという5000個の数字に変換できた。一旦ここで、データの様子を見てみよう。ここでもひと工夫する。もしそれぞれのデータが座標(x, y)のように2個で構成されるなら2次元の画面に描画できるが、5000個で構成されるなら5000次元も必要だ。そこで「UMAP(Uniform Manifold Approximation and Projection)」という手法を使う(紹介は門脇ほか(2019)など)。
UMAPは、データ間の「距離」や「関係」を考慮して、似たデータは近く、違うデータは遠くに配置していく。するとデータ間の関係を保持しつつ、2次元や3次元のデータに変換できる(7)。ここで5000次元のTF-IDFを2次元に圧縮すると、各文書を2つの座標で示せるようになる。
そこで作成されたのが以下の図3だ。あくまでもデータ間の距離や関係を保持しているだけなのだが、大事なのは白三角で示している「ハリポタツアー」の位置だ。画面の中央に分布しており、左上には黒四角の科学博物館や黒三角の民族博物館がある。そして右下には白四角のディズニーランドや白丸のUSJがある。
ここから、人々のハリポタツアーに対する感想は博物館(科学博物館や民族博物館)と遊園地(ディズニーランドとUSJ)の中間で、完全に博物館とも遊園地とも言いがたいと解釈できる。でもこれはアドホックで偶然に依存するため危険だ。もう1つ分類という課題を解いて考察をくわえたい。
分類とは、与えられた入力にラベルを与える処理だ。つまり、5000語のTF-IDFを持つ文書にラベル(博物館・遊園地)を貼っていく作業になる。手でやると大変だが数字に変換してあるから、「ロジスティック回帰」という先人の知恵を使える。まずはラベルを貼る。ジブリ美術館やハリポタツアーは博物館か遊園地かが不明なのでラベル貼りはしないで脇に置いておき、その他に博物館なら1、遊園地なら0とラベルをつける。そして5000次元の数字を0か1かに分類させる。
中学生の頃にy=ax+bという式を習ったが、TF-IDFがx1, x2, … x5000と続くと考え、それぞれに対応する係数a1, a2,... a5000も用意する。かけ合わせた和であるa1x1 + a2x2 +... a5000x5000 に「シグモイド関数」という「値を0と1の範囲に収める関数」を適用すると、TF-IDFを0–1の値に収める操作が可能になる。あとは博物館を示すTF-IDFなら1、遊園地なら0に近づくように係数a1, a2, … a5000を調整する。
すこし抽象的だったので、各単語に対応する係数の具体例を見てみよう(図4)。図のx軸は係数の値を示しており、正の係数を持つ「展示」のような単語は博物館らしさを増し、負の係数を持つ「アトラクション」のような単語は遊園地らしさを増すだろう。
ハリポタツアーの感想を示す5000次元のデータにも同様のa1, a2, …a5000をかけてシグモイド関数を適用すれば、0から1の値になる。実際には0.3のような数字になるので、0.5以上は1とする。大量に集めたハリポタツアーの感想は1(博物館)になるだろうか。
係数をかけた結果、博物館と判定されたのは全体の21.8%だった(8)。この結果はなかなか興味深い。というのも、としまえんの跡地に「開園」した「エンターテイメント施設」に対する感想に対して、5分の1程度の人が「博物館」と分類できる感想を述べたのだ。もちろん科学博物館や民族博物館ほど「博物館」らしくはないし、USJやディズニーランド寄りなのかもしれない。でもたしかに、一定数の人は「博物館」とみなす感想を述べており(9)、これはもちろん遊園地ではありえない結果だ。
さて、今回は単語というより文書を数字で表現したが、単語でも似たようなことができる。つまり文脈(どのような単語と共起するのか)を見れば単語の意味はわかる(岡﨑ほか, 2022)。これを分布仮説と呼び、たとえば「日比谷」や「渋谷」が周囲に取りやすい単語は「焼きそば」のそれらに比べればずいぶんと違うだろう。分布仮説により単語を数字で表現する話については、もうすこし先にする。
コラム:クラスタリングと鶏卵
つぎのトピックに移る前に、距離や類似度を扱うとクラスタリングで見たようにカテゴリーの形成が可能になる点を共有したい。書籍『記号創発ロボティクス』 (谷口, 2014)が詳しく、ここでは概要だけ紹介する。人間の知能を理解しようとする際、現象を計算機で構成していく方針で考察する手法がある(10)。例として、「概念形成は可能だろうか」という問いを挙げてみよう。ひらたく言えば、「タヌキ」という概念、つまりカテゴリーの形成は可能だろうか。
「タヌキ」というカテゴリーを形成するために、まずは「ムジナ」や「キツネ」を含まない、純粋な「タヌキ」に属する個体を集めていくとする。しかしこれは最初からおかしい。というのも、「タヌキ」に属する個体を集めるということは、先に「タヌキ」を知っておかねばならない。でも今やろうとしていたことは「タヌキ」というカテゴリーを形成するというタスクだったはずで、どちらが先か分からないニワトリタマゴになってしまう。
この問題を書籍では、K平均法と呼ばれるクラスタリングの手法を使って解決する。前回の話でもクラスタリングを使ったが、タヌキやムジナなどのカテゴリーの情報は知らないものとして使わなかった。むしろ「画像から分かれるのだろうか」という問いがメインで、タヌキとムジナは難しかったがキツネとはカテゴリーが分かれるという結論だった。
なぜ紹介した書籍や前回の話の中で、ニワトリタマゴにならなかったのだろう。それは各画像がお互いに「それっぽさ」を計算できる状態だったからだ。つまり、お互いの距離や類似度を計算できたので、「いくつのカテゴリーに分けるのがよいか」さえわかれば事前にカテゴリーがなくとも似たものグループ(=カテゴリー)を作れた。タヌキとムジナとキツネなら、普通の人なら2つで十分だ。でも、食味や分類に興味のある人にとっては3になるかもしれない。
参考文献
岡﨑直観., 荒瀬由紀., 鈴木潤., 鶴岡慶雅., & 宮尾祐介. (2022). 自然言語処理の基礎. オーム社.
門脇大輔., 阪田隆司., 保坂桂佑., & 平松雄司. (2019). Kaggleで勝つデータ分析の技術. 技術評論社.
谷口忠大. (2014). 記号創発ロボティクス: 知能のメカニズム入門. 講談社.
(1) https://www.wbstudiotour.jp/
(2) https://www.ikejiriseiji.jp/news192/
(3) https://youtu.be/mQuvkCMwKLw?t=1409
(4) https://elaws.e-gov.go.jp/document?lawid=326AC1000000285
(5) 今回も実験のファイルはGoogle Colab からアクセスできる。
(6) HTMLファイルからreview-full-textというクラスのspanタグを抽出して日本語の感想に制限する。手順などは補足資料にまとめてあるので、興味のある方は参考にしてほしい。
(7) 概要の解説動画 https://www.youtube.com/watch?v=eN0wFzBA4Sc
(8) 交差検証の精度は0.94なので分類精度が低いという話ではない。
(9) ハンズオンの資料では好きな文を分類できるのでぜひ遊んでみてほしい。
(10) 「構成論的なアプローチ」と呼ばれる。
-
- 2023年10月17日 『2. 言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議:タヌキと魔法から見る言語表現 岸山健(法政大学文学部英文学科ほか非常勤講師)』
-
タヌキと魔法から見る言語表現
 図1. タヌキ(左)とムジナ(右)
図1. タヌキ(左)とムジナ(右)
 図2. 筆者が取り寄せたアナグマ肉
図2. 筆者が取り寄せたアナグマ肉
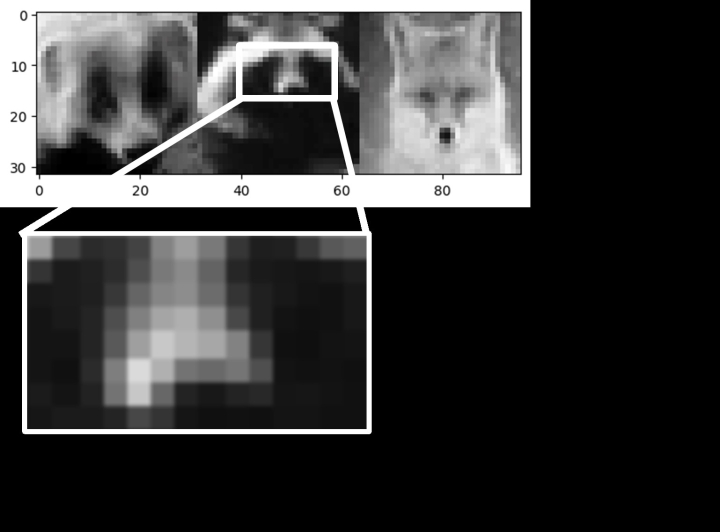 図3. ムジナとタヌキ、キツネの画像と数字的表現。黒を0、白を255と表現すれば、結局は数列だ。比較対象としてキツネも右に加えている。
図3. ムジナとタヌキ、キツネの画像と数字的表現。黒を0、白を255と表現すれば、結局は数列だ。比較対象としてキツネも右に加えている。
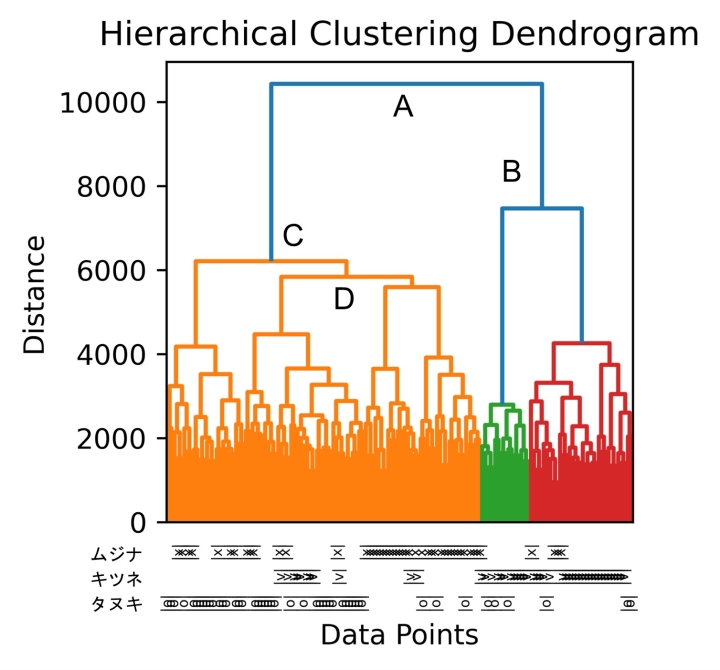 図4. 画像の類似度を用いて作成したデンドログラムを示す。 クラスター間の距離が大きく異なる部分で色を分けている。
図4. 画像の類似度を用いて作成したデンドログラムを示す。 クラスター間の距離が大きく異なる部分で色を分けている。
言語学関連の講義を除いて今でも強く記憶に残っているのは、法学や倫理学の概論だ。毎度の講義では広い教場の最前線を陣取ってノートをカリカリと取っていたので、さぞ教授に圧をかけてしまっていたと思う。けれど、それだけ内容が引き込まれるものだったのだろう。
電気という概念がない時代に法は電気泥棒を裁けるだろうか、「胎児」は人間だろうか。講義はそんな問いを魅力的に導入していた (1)。それぞれに対する答えは日常の感覚と異なり、新鮮な観点を与え、好奇心を強く刺激した。なにより、倫理を法律に委託していた当時の自分に疑問を投げかけるような時間でもあった。
言語とルールに関わる興味深い話も講義では多く紹介された。本題に移る前の前提として、そもそも社会のルールと単語の重要さを感じられる話はたくさんある。数字できっちり定義が決まっている単語もあれば、自然言語に定義を任せている場合もある。前者、つまりキッチリと単語を数字で定める例として、トラックのタイヤの数や船舶の長さ、ロフトの高さの定義に触れてみよう。
高速道路でタイヤを浮かせているトラックを見かけることがあるが、これは走行時の車軸数を減らし車種区分を「特大車」から「大型車」に変えて料金を浮かせるためだ (2)。船舶の全長も199mという妙に半端な長さが目立つが、200mを超えて大型船に分類されると運航上の制約が生じる (3)。他にも、ロフトは高さが1.4mを超えると階になり、耐震基準や固定資産税が変わる。このように数字でカテゴリーを分ける例は多くある。
それに対して、数字で決めずに自然言語のカテゴリーをそのまま持ち込んで解釈が難しくなったケースもある。そんな数字で片付けられないトピックを2つ紹介したい。1つは「たぬき・むじな事件」と呼ばれるもので、もう1つは映画ハリーポッターの舞台裏や世界観を楽しめるエンターテイメント施設、「スタジオツアー東京」だ。まず、タヌキとムジナの話から始めよう。ここでは自然言語のあやふやさを数字に落とし込むことのメリットを共有したい。
タヌキと法の裁き
突然だが、タヌキとムジナの違いをご存知だろうか。この質問をすると大抵の場合は「いや同じでしょ」という、問い自体が誤りであるかのような反応が得られる。たしかに、ことわざの「同じ穴の狢(ムジナ)」は「一見して無関係に見えても実は同類の喩え」だから、その反応はもっともだ。
でも、現代の語彙で「ムジナ」が指すのはタヌキではなくアナグマであり、上に出てきた「同じ穴」もアナグマが掘る穴のことだ。このタヌキとムジナ(アナグマ)は、図1の通り異なる動物だ。
この違い、実は言語・食文化・法律の面でいろいろと深堀りのしがいがある。言語の面から言えば、ムジナという単語はアナグマやタヌキを示す場合もあるのと同時に、タヌキという単語はタヌキだけでなくアナグマを示す場合もある。この混乱は後述する『狸考』という文献で紹介されているが、食文化や法律の面でたびたび議論になってきた。
さきほど挙げた法学の講義でも「たぬき・むじな事件」と呼ばれる事件が扱われた。これは法律と単語を考えるよいきっかけになるがややこしい。だからまずは手頃な食という観点から近づいてみよう。
多くの人はタヌキもムジナも食べた経験がないと思うが、食味の違いは『狸考』という文献に狸汁の記述がある(佐藤1934,pp.24–26)。これはデジタルアーカイブ (4)からもアクセスできるし短いので、ぜひ一読して見て欲しい。当時まとめられた食レポには以下のレビューがある。
其肉臭不可食(本朝食鑑)
みなみな鼻を掩ひて吐き出したり(關の秋風)
それにしても「其肉臭不可食」とは端的ながら、食べログも泣き出すレベルの辛口だ。ここまで書かれると喰われたタヌキがいたたまれない。また現代のレビューでも、野食ハンターの茸本朗 さん (5)は「動物園の臭い」と評している(茸本,2019,p.150)。ここから考えると「タヌキ」は嗅ぐにつらいようだ。
それに対してアナグマの方はというと、同氏のブログ (6)では、油脂は薩摩黒豚と互角に戦える風味だという。また過去の『狸考』では「舌鼓打つ狸汁かな」との絶賛レビューも紹介されている。そこで『狸考』では狸汁にタヌキだけでなくアナグマの場合もあったと想定されており、時代や地域によってタヌキという単語がアナグマを指しえたと推察する。
実のところ、筆者もアナグマ肉を取り寄せて (7)食べたことがある(図2)。油脂が多いという先行研究 (8)があったので、肉より油の方が多い真っ白なアメリカのベーコンくらいを覚悟していた。丁寧に小分けにされて届いたアナグマ肉を見ると、冬と比べて夏の非餌づけ個体だったからだろうが(金子&丸山,2005)、脂と身のバランスはよかった。
解凍したアナグマ肉を野菜とフライパンで炒めると乳成分を感じさせる甘い香りが立つ。自分の嗅覚が壊れたのかと不安になるが、読んだレビューにも甘い香りがするとあったので間違いではなさそうだ。火が通りギリギリを攻めてレモンと塩で食べても、やっぱり油脂の部分からは甘みを感じたし、肉からも強い旨味が伝わってくる。飲み込むときに甘い香りがふっと抜けるのが面白い。
フライパンに残った肉と野菜に手前味噌(文字通り)と、河川敷で採取して冷凍保存しておいた道草(ノビル)を加えて狸汁とした。すでに焼肉で食味を堪能していたので強い感動はなかったが、噂に違わずの肉感と油脂の上品さには驚いた。はたしてこの肉に対し、酷評は得られるだろうか。
たしかに動物に興味のない人が実物を比較せず、あるいは食味の違いを考えずにいたら、間違えるかもしれない。さらに間違えたところで皿の上に楽園がくるか動物園がくるか程度の差だ。でも大正時代では困ったことに、自分が裁かれる側になる可能性もあった。
さきほどのレビューにあった通り、ムジナ(アナグマ)は美味だ。遡って1924年(大正13年)、栃木県のある猟師がムジナと思われる動物を発見し村田銃で狙撃を試みたそうだ。しかし狙いは外れ、ムジナは近くの洞穴に逃げ込んだ。猟師は狩猟に成功したムジナと呼ばれる種がタヌキと別種であることを確信しており(現代でもその通り)、洞穴を岩で塞いで閉じ込め、最終的には2日閉じ込めたのち猟犬に仕留めさせた。
ややこしいのはここからで、実は岩で閉じ込めた時点と仕留めた時点の間に、タヌキの狩猟を禁止する狩猟法が施行された。岩で閉じ込めた時点で狩猟が完了していたからセーフという論点もあるのだが、問題は裁判で「タヌキとムジナは同種だ」と仮定されたことにある。ここでタヌキとムジナが同種という前提をめぐって議論になるが、該当地域だけでなく別種との認識が散見されることや、捕獲のタイミングを考慮して最終的に無罪となった (9)。
ただ、この裁判の前提である「タヌキとムジナは同種」という話も、ことわざや食レポの混乱から考えても強く批判できる自信はないし、法律に必要な抽象性(森田,2020,p.67)の結果だったのかもしれない。というより、そもそも種に名前をつけるというのは、見た目だけでなく生態とその相互作用まで含めなければならない難しい作業だ (10)。
トラックやロフトのように、人間が「AはBとする」と数字で定義するなら簡単だが、生物の名前などは世間の価値観や分類学(taxonomy)に外注することになる。すると上記のような「いやそもそもタヌキってなんですか」という、分類学が抱える問題に衝突することになるのだ。
だから区別をしなかった、裁判に携わった人を責められはしない。でも、見た目だけにヒントを制限した場合、このタヌキとムジナはどれくらい区別がつかないものなのだろうか。可視化もかねて少し検証してみよう。
数字による表現とクラスタリング
タヌキとムジナの近さなんて興味ないかもしれないが、カテゴリーの近さを数字で(つまり定量的に)表現するのは価値がある。今回は画像の近さを比較するが、渋谷–日比谷のように意味の近さを比較できたらなにかと便利だ。言語の距離はのちに考えるとして、まずはわかりやすい画像の比較から入る。
でも、そもそも画像ってなんだろう。人間の目がどう世界を見ているかはさておき、少なくとも白黒画像は「ピクセル」で表現できる。図3下のように白黒画像を拡大してみると、0(黒)から255(白)の輝度を持つピクセルが見える。これが並んでいて32×32ピクセルなら32個目で行替えして次の行だ。この繰り返しだから、サイズが32x32のタヌキやムジナの画像は1024個のピクセルで表現できる。
単純に比較するなら、この1024の画像をそれぞれ比較すれば良い。図3上のムジナとタヌキで言えば、背景の左上はムジナでは明るくタヌキでは暗い。ピクセルごとの差を足し合わるとマイナスとプラスで打ち消しあってしまうので、マイナスをとっぱらってから差を足し合わせる。すると、同じ部分で異なる輝度を持っているほど、距離は遠くなるわけだ (11)。
これで画像間の距離が求められる。そして距離を求められる時にはクラスタリング(clustering)という、似ているもの同士をグループにまとめる手法が使える。データをグループにまとめると、データのパターンや関係を見つけやすくなるのだ。だから気持ちとしては、似ている「タヌキ」と「ムジナ」が先にまとまり、その「タヌキ+ムジナ」と「キツネ」が後でまとまってほしい。後でまとまるということは先に分かれるとも言い換えられる。したがって、「タヌキ+ムジナ」と「キツネ」が先に分かれ、「タヌキ」と「ムジナ」が後で分かれることを期待しているともいえる。
重要なのは、見た目しか使わないということだ。ここでの問いは「見た目だけで区別できるのか」なので、「これはタヌキですよ」とか「これはムジナですよ」というラベルを使うのはルール違反だ。今はそうしたカテゴリーを教えてくれるラベルがない、環境の色や対象の見た目だけで区別できるか、という話だ。
でも、なぜ急に上でキツネが出てきたんだろうか。キツネとタヌキは分かりやすそうだ。それに比べて、タヌキとムジナはどれくらいわかりづらいだろう。このように、キツネvs.タヌキの分かりやすさと比べていると、タヌキvs.ムジナがどれくらい分かりづらいかを考察できるからだ。
まずはデータを集めよう。地道にGoogle画像検索の結果を表示させ、スクリーンショットで動物の顔部分を淡々と保存する。タヌキはTNK、ムジナことアナグマはANG、きつねはKTN…。特に意味はないが48枚ずつ、正面の顔を保存した。するとTNK48.pngのような画像ができる。
先に述べた距離を用いてクラスタリングでグループを作っていく手法を使う。より詳しく知りたい人は『機械学習入門』(高村,2010)を参考にして欲しい。このクラスタリングをすると、デンドログラム(dendrogram)、つまり、木っぽい(dendro-)図(gram)を書ける (12)。
ともかく、作成したデンドログラムを見てみよう(図4)。ひどく分かりづらいが、上から見るとAと書いてある部分から分かれており、つぎにBで右は分かれている。これはAの左右の違いはBの左右の違いより大きかったことを示す。そして3番目に左はCで分かれているので、Bの左右の違いがCの左右の違いより大きかったことを同じく示している。
分かれていった先には画像が本来144枚(3種類×48枚)あって見えないので工夫した。図の左下に示すように、三つの行(上からムジナ、キツネ、タヌキ)で、分かれた先が示す動物を示してみた。例として右下は中央行(キツネ)が密集して重なっており、これは右(B)に分岐したのはキツネが多いことを示す。それに対してCに分岐したグループは、上の行のムジナと下の行のタヌキが多い。Dで右に分岐して、ようやく一番上のムジナが密集して分かれている。
この図の解釈としては、まずAの時点で左と右に分かれる。左のCにはタヌキ・ムジナのグループがあり、右のBはキツネのグループだ。そしてつぎに分かれるのはBだから、同種であるキツネのグループ内の差の方が、ムジナ・タヌキのグループ間の差より大きく先に分かれたと解釈できる。つまり、ムジナとタヌキが分かれるのは、Cを分けた右(D)で、さらに分けた右の部分でようやく、ということになる。
したがって、キツネが一発目で分かれたのと比べると、タヌキとムジナは随分と分かれない。また、分かれた時点もキツネの中の差を分けるよりもわかりづらいと解釈できる。この実験はGoogle Colabに詳細を書いてある (13)。
https://github.com/kishiyamat/la-kentei-yaminabe/blob/main/notebooks/tanuki.ipynb
数字を使った表現にすると、いくつかうれしいことがある。1つは似ている・似ていないという表現に対して、「どれくらい」という尺度をくわえられることである。これを「ちょっと」や「かなり」といった言葉だけで表現するのは骨が折れそうだ。骨を折って表現したとして、他の事例との整合性を保証し続けられるだろうか。たとえば、上の比較にアライグマが参戦したらどうだろうか。
もう少し下心を共有すると、すでに存在する手段を再利用できるのも強い。今回使ったクラスタリングも可視化も、ほんの少しのスクリプトを書くだけで実現できる。もちろん、手法によって満たすべき前提や概要くらいは理解しておきたいが、理論や細かい実装まで追うのは難しい。しかし数字まで抽象度を高めると先人が培った手段も多く使える。これは魅力的だ。
今回はタヌキやムジナに対する画像を引っぱってきて、単語を数字で表現する工夫を共有した。これは単語をデータで表現する1つの手段だ。でも実は、画像がなくても単語は表現できる。だって単語の周りにはたくさん「単語」というデータがあるのだから。つぎに単語の分布で文書を表現、分類する方法を考えてみよう。
参考文献
金子弥生 & 丸山直樹. (2005). 東京都市近郊におけるニホンアナグマ (Meles meles anakuma) の体重及び栄養状態への地域住民の餌づけの影響. 哺乳類科学,45(2),157–164. 日本哺乳類学会.
佐藤隆三. (1934). 狸考. 郷土研究社.
高村大也. (2010). 言語処理のための機械学習入門. コロナ社.
茸本朗. (2019). 野食ハンターの七転八倒日記. 平凡社.
森田果. (2020). 法学を学ぶのはなぜ? 気づいたら法学部、にならないための法学入門. 有斐閣.
(1) 胎児は民法と刑法で定義が異なり、縄張り語と呼ばれる。
(2) https://kuruma-news.jp/post/514285
(3) https://www.data-max.co.jp/article/62839
(4) https://dl.ndl.go.jp/pid/1076759/1/1
(5) そもそも「野食」とは、野にある食材を楽しむ行為のことを指す。茸本朗さんと言えば、野食ハンマープライスというブログを執筆されていて、最近ではYouTubeチャンネルも運営している。漫画『僕は君を太らせたい!』の原著者でもある。狸汁のほかに、アライグマで二郎ラーメンを作るという企画もあって面白く、レビューの観点や表現力が豊かで激推ししている。ちなみに、意外と大学でも食材はあり、たとえば東大の駒場キャンパスでもさまざまなものが楽しめる。界隈で有名な記事に、中澤恒子先生が退官されたときの記事『<駒場をあとに> 駒場の風景』がある。
(6) https://www.outdoorfoodgathering.jp/meat/anaguma/
(7) たとえば「米とサーカス」 https://kometocircus-online.com/がある。実店舗は一般的なジビエにくわえて昆虫食も揃っているので、昆虫食ビギナーの筆者にはなかなか恐れ多くて足を運べない。オンラインでポチれるくらいがちょうど良い。ただしウェブでも食に寛容な人以外は心する必要がある。
(8) https://chikatoshoukai.com/eat-barger/
(9) この裁判は東山動物園や先述した佐藤(1934)でも紹介されている。
(10) ハシブトガラとアメリカコガラは見た目での区別が難しく生態を考慮せねばならず、ノビルとスイセンの球根部、タマゴタケとベニテングタケ、状態によってはぱっと見では区別できない。
(11) 適切に計算すると「ユークリッド距離」と呼ばれる値になる。
(12) 横文字だらけで恐縮だが、"dendro-"は「木」を意味するギリシャ語に由来している。神経細胞の一部に樹状突起というのがあるが、あれもdendriteという。上下ひっくり返すと木に見えるからデンドログラムだ。
(13) 実験に使ったノートブックを配置している。「Open in Colab」というボタンを押すと、Colabが起動してコピーを作成し実行できる。最初の「はじめに」で述べた通りに実行ボタンを押すと「警告: このノートブックは Google が作成したものではありません。」と言われるので、著者を信頼している場合は「このまま実行」を選択してほしい。信頼していない場合は信頼してほしい。
-
- 2023年10月10日 『1. 言語学闇鍋エンジニアリング―プログラミングで探る言語の不思議:はじめに 岸山健(法政大学文学部英文学科ほか非常勤講師)』
-
はじめに
 図1. 姉は日比谷での出来事を話しているのに、父は会話の背景として渋谷を想定して話を進めていた。
図1. 姉は日比谷での出来事を話しているのに、父は会話の背景として渋谷を想定して話を進めていた。
 図2.「日比谷・渋谷」をアルファベットで比較してみると、四角で囲んだ部分の音色は似ているように思える。
図2.「日比谷・渋谷」をアルファベットで比較してみると、四角で囲んだ部分の音色は似ているように思える。
 図3. 可愛いタヌキ・ムジナの話や某魔法学校、ホーミーやAIを扱っていく。パソコンを使えると内容をより楽しめるが、なくてもよい。
図3. 可愛いタヌキ・ムジナの話や某魔法学校、ホーミーやAIを扱っていく。パソコンを使えると内容をより楽しめるが、なくてもよい。
 図4. Colabノートブックの編集画面
図4. Colabノートブックの編集画面
この原稿を書いているとき、身の回りにいる好奇心旺盛な友人や研究者、熱心に授業を聞いてくれる学生やお世話になった先生方の顔を思い浮かべている。言語に関心を寄せる人たちに、どんな面白い話を共有できるだろうか。インターネットに広まっている話では退屈させてしまうし、あまり堅苦しい話をしすぎても興味を持ってもらえない。
そこで、これまで出会ってきた少しマニアックな言語に関する話を、エンジニアの角度から伝える方針をとってみたい。いろいろな話を混ぜてはいくけれど、いわゆる単語や音声、文法といった言語の異なる側面を、「え、こんな角度から見るの?」と面白がってもらえたらうれしい。
話の範囲は、動物の名前から法律、耳の聞こえ、カードゲームやAI、ホーミー(モンゴルで奏でられる歌唱法)まで闇鍋状態だ。でも混ぜているのは1人だし、材料も把握しているので味は整うはずだ。そこで、まずは個人的なエピソードから始めたい。
日比谷? 渋谷?
これは数ヶ月前、両親と姉を乗せていた車の中での話だ。不慣れな首都高を緊張して運転しながらも、助手席に座る父と後部座席の姉の会話に違和感を覚えた。というのも、姉は日比谷について語っているのに、父の頭にはどうやら渋谷の風景が浮かんでいるらしかったからだ。
あとから思い出したのだが、過去にもこの手の不一致は何度かあった。すぐ浮かんだのは、大学近くにある中華料理店での会話だ。そこのメニューには「ミソソバ」という、甘辛いひき肉の上にキュウリと椎茸をのせた一杯がある。食べているのを眺めながら、父は「ミートソバ、どう?」と言った。「ミソソバだよ」と訂正したけど、父は「うん、ミートソバおいしい?」と聞き返してきた。何度「ミソソバ」と言っても、父の耳1には「ミートソバ」として届いていたようだ。
これだけだとよくある聞き間違いの話になってしまうが、そうではない。言語の学問に触れた身として、この手の謎は放置しがたい。というのも、仮に耳が遠いだけなら会話の全体が成り立たないはずだ。でも体感で会話は成り立っていて、突如として噛み合わなくなる。だから単純な耳の遠さではないはずだ 2。そこで疑問に思った。日比谷と渋谷、ミソソバとミートソバ、この背後にある誤解の原因があるとするなら、それは一体何だろう。
問い:なぜ「日比谷」と「渋谷」、「ミソソバ」と「ミートソバ」は聞き間違えられたのか。
最初に気づくのは、どちらの事例もカテゴリー的には正しいという点だ。つまり、「Xの公園に行った」にある「X」は、日比谷も渋谷も自然に「場所」として受け入れられる。同様にミソソバもミートソバも「食べ物」らしいから「この店のXは美味しい」という文脈で自然だ。つまり、それぞれがカテゴリー(場所・食べ物)を示す名詞としても適切だ。
カテゴリーや品詞3が適切であるのに加えて、音も似ている。日比谷と渋谷はアルファベットで「hibiya」と「shibuya」と表現できる。市ヶ谷(ichigaya)などと比べれば、この2つは音の振る舞いやリズムが似ている。たしかに異なる音の組み合わせ(h–shとi–u)は存在するが、学術的な厳密さは後述するとして、共通の音色を感じる(図2)。
日々の会話から、iとuの組み合わせを父は聞き分けられていると感じる。それを踏まえて、「原因は、h–shやs–tの聞き分け能力にあるのではないか」という強めな仮説を立ててみよう。この仮説を追求すると、これらの音のペアのどちらか、あるいは両方がhとsh, sといった「摩擦音」を含むことに気づく。
この「摩擦音」とは、日本語の中の「サ行」や「ハ行」にも現れ、静かさを求めるときの「シー」とか、熱い麺を口に運ぶ前の「フー」という音に代表される。これらはまさに、指を摩擦させる際の音に近い。
そこで仮説を「摩擦音が聞き取れていないのではないか」と派生させ、これを試す目的で実際に指を擦り合わせてその音を父に聞かせてみると、驚いたことに、その音をほとんど聞き取れなかった。
理由はともかく、摩擦音が弱いのか。この発見以降、父との会話では意識的に摩擦音を避けるようにした。例えば「指定の」という表現を「特定の」と変えるなど、その音を避けつつ意味の通る表現を選ぶ。すべての音が聞き取れないわけではない。特定の種類の音だけだから、別に大声で話す必要もない。自然と話す速度は遅くなるし、早口な自分にはちょうどよいとすら思う。
幸い父も職業柄、言語に関しては明るいので「摩擦音の聞き取りが苦手だね」という話はスムーズに伝わった。後ほど説明するが、人の知覚を考えれば聞き間違いの要因は複数ある。ただ、ここでの暫定的な答えは以下になる。
暫定的な答え:特定の音(上の場合、摩擦音)の聞き分けが困難であり、さらに単語の品詞やカテゴリーも同じだったから聞き間違えた。
これで少しだけスッキリした。とはいえ日常生活や労働といった場面で、こうしたケースをどれだけ認識してこられただろうか。こういう細かな違いをただの「耳の遠さ」として端折ってしまっていたかもしれない。
音の種類にも、人の感じる強弱には差がある。こうした違いは音以外の感覚にも存在するかもしれない。となると日常で聞き逃していた、見落としていた事や物が多かったのかもしれない。これから聴力や視力を含めた感覚、あるいは認知機能を将来的に失っていく。手放す前に、先人の立場を考えることで何か学べる気もする。
本連載の構成
上述した聞き間違いは個人的な話だったけれど、2つの理由から導入として使った。1つは単に、自分の中で「言語を深く学んでいてよかったな」と感じた瞬間だったからだ。高齢化社会をサバイブする我々も、いずれ行く道であるので他人事ではない。特定の音が将来的に聞き取れなくなる覚悟はしておいてもよいかもしれない。
もう1つは、後続の話に対して適切な導入に思えたからだ。身の回りにある言語のトピック、つまり単語や音、構造を掘りさげていくうえで、単語の聞き取りはよい例となる。というのも、カテゴリー(あるいは単語の意味)の近さや音、品詞(あるいは構造)の話をバランスよく含んでいる。したがって、聞き間違いの話はときおり引き合いに出される。
念のために断っておくと、以降で紹介するトピックは一見すると上の話と関連がない。法律と単語(タヌキ vs. ムジナ)の話であったりホーミーと呼ばれる歌唱法の話であったり、ゲームや法律の構造、AIの話だったりする。でも言語情報の処理という意味で、疎ではあるが結合している。以下、5つのトピックで言語の不思議な部分に焦点を当てていく。
最初に共有するのは単語と法律の話で、個人的にはお気に入りだ。大正のタヌキ・ムジナの例では食や法律で単語を区別する重要性や難しさ、令和の某魔法学校の例では単語や文書を数字で表現する方法を考える。
つぎに、ホーミーと呼ばれる歌唱法や音を可視化する方法を共有する。人がいかに器用に音を聞き取っているかという話を難聴の部分でするが、その前に音とはなにかを基礎から共有したい。教科書的に説明してもよいが、モンゴルに伝わる特殊な歌唱法を題材とする。音とモンゴルへの知識を深めたホーミービギナーになれるだろう。
3番目では単語の聞き間違いの謎に迫る。専門的には「異聴」と呼ばれる聞き間違えの背景やメカニズムを紹介する。この謎に迫るためには人が音声を聞き取る手順から考えた方がよい。人の聴覚をシミュレーションする研究や「聞き間違えない国語辞典」というプロジェクトに言及しつつ、異聴を引き起こしやすい語の候補を考えていく。
4番目の話題は文の構造に関する話題となる。ゲームに出てくる文の読みやすさ(可読性)から、法における言語の多義性について考える。可読性に関しては、マジックザギャザリング、通称MTGというカードゲームがあるのだが、それに関して起きた不思議な出来事の導入から始める。多義性に関しては、横入り、ズル込み、なんでもいいが「列への割り込み」に関する法律の解釈の導入から開始する。どちらの例も文を理解する過程に関して面白い示唆を与えてくれる。
最後のトピックは言語と計算機の関係で、主にAIの活用に焦点を当てる。プログラミング言語を使うと、生成AIの扱いがどう変わるのかを専門家に教えてもらう。詳しくない人でも自由に生成AIを使いこなすコツも共有する。
以上が各トピックの概要になり、大まかには3種類の進め方を取る。1つは著者が身近で触れた言語に関するエピソードや疑問を紹介する。これは世に出回っていない、手や足で稼いだ新鮮なネタを心がけた。近年はYouTubeをはじめとして質の高いコンテンツが出回っており、耳や目の肥えた方にも満足な話を提供したい。
第2は専門家に意見をもらう形式になる。世界には思わず頭を突っ込んでしまいたくなる話が溢れているが、踏み込んだが最後、沼の深さにハマって身動きが取れなくなる場合がある。研究という、知識を生み出す活動をしているからには雑な情報は削減したい。そこで専門家に補足していただく形で、言語の面白い話を掘りさげていく。
最後は、その面白い話をパソコンで確認する作業になる。一見すると、いかにも言語とは文系的で、パソコンはいかにも理系的で相性は悪いように思われるが、そんなことはない。ここでのパソコンは目的ではなく手段であり、少し触れるだけで言語の調理法も増やせる。言語自体に直接は触れられないが、ソフトウェア経由なら触れられる。
そこで、言語の学問である言語学と道具としてのプログラミングを眺める。もちろんパソコンがなくても読み進められる形式にはしているので安心していただきたい4。
言語学とプログラミング
人文科学5としての言語学と、情報処理技術としてのプログラミングの両方を扱う人は珍しいと言われる。自身がプログラミングを始めたのも、偶然アメリカの大学でアカデミック・アドバイザーから「言語学好きならこれも好きかもよ?」と勧められたのがきっかけだった。よく考えると1年きりの留学生の履修科目をマンツーマンで考えてくれたなんて非常に贅沢だが、これがなければ触れなかっただろう。
言語学にはもともと留学前から興味を持っていた。言語学では、言語の普遍的な性質に関して仮説を立て、データで検証する 6。ここでの言語とは、音(あるいは文字や動作)やそれらの規則、単語、文の構造、談話など、分けた範囲を指す場合が多い。でも、範囲の組み合わせを研究する分野もあるし、言語の性質だけでなく、獲得や運用の仮説を検証する分野もある。
対してプログラミングは筆者にとって道具だ。言語学の対象である言語や「人間が言語を理解する処理」は手で触れられない。でもプログラミングを使えば言語だけでなく処理にさえ触れられる。プログラミングを使えば仮説を検証する方法を増やしたり、検証する仮説自体も作れたりするという意味でも有用に思える7。
これから、上に紹介したトピックをさまざまな角度から眺めて触っていく。再三になるが、パソコンを使えなくても手を動かさなくてもよい。でも、もし環境が許すならば一緒に手を動かしてみてほしい。言語や処理に触れられる楽しさを感じてしてもらいたいし、きっと今までとは違う視点を共有できると思う。そこで最後に、プログラミングを使う練習をしてみたい。単に読み物とする場合、ここは一旦飛ばしてもらって、興味が出たら実習に戻ってきてほしい。
今回はGoogleが提供してくれているColab(正式には「Colaboratory」)という環境で、プログラミング言語Pythonを使う。スタートする方法は2種類ある。ここでは、本当に初めてという人向けに説明するので、以前使ったことがある人は途中から合流してほしい。
まず、「Colaboratoryへようこそ」などと検索すると「Colaboratoryへようこそ - Colaboratory」というページが検索結果の最初にでてくるだろう 。クリックすると「ノートブックを開く」と書かれたポップアップが表示されるので、左下にある「+ノートブックを新規作成」と書かれた青いボタンをクリックする。そうすると、上記の手順を終えると図4に示す画面に移る。これで準備は完了だ。
たとえば「コードセル」と呼ばれる図4で灰色がかっている部分(左に1と行数が書いてある)では、インタラクティブに操作できる。つまり、値を計算して変数に保存し、結果を出力するようなPythonスクリプトを記述・実行できる。
試しにコードセルをクリックして半角英数で1+1と記入してみよう 。人によっては初めてのPythonコードを書いたことになる。そしてコードセルの左側にある実行ボタン(再生マーク)をクリックするか、キーボードのショートカット「command+return」または「Ctrl+Enter」を実行する。きっと2と表示されただろう。
もしかしたら「え、だからなに?」と思ったかもしれない。でも、この1+1という計算の瞬間、我々は頭をまったく使っていない。もう少し(場合によってはかなり)頭を使う作業を、外部のパワフルな存在に委託できるとしたら、どうだろうか。
ここでは実行さえできれば十分だ。さらに言うと、実行しなくても9割は読み進められる。でも、最後まで実行してみればきっとプログラミングの力強さや魅力を実感できるはずだ。
(1) この表現が厳密には正しくないことは、おそらく話が進んだ段階で共有できる。
(2) この「AならばBのはずだ。でもBでないならばAでない」という思考回路を多用してしまう。少し冗長で読みづらいかもしれないけど、省くと行間を補わせる役目を押し付けてしまうのでご容赦を。
(3) 品詞には名詞や動詞、形容詞や副詞などがある。本文中の例で言えば、動詞の「笑う」は「今日、Xに行ったんだよね」のXには入らない。仮に「笑う」が入っていたなら、多くの人は動詞ではなく名詞として考え、「あぁ、「笑う」というお店があるのね」と解釈するはずだ。
(4) 近年の環境の改善からプログラミングは本当に簡単になったので、ぜひ身近にいるパソコンに少し詳しい人(GmailやGoogle Driveを開ける程度)に聞きながら挑戦してみてしい。
(5) 政治・経済・社会・歴史・文芸・言語など、人類の文化全般に関する学問の総称。物理学などは自然科学に属し、社会における人間行動を科学的,体系的に研究する経験科学の総称に社会科学がある。
(6) 言語学という字面を分解すると、いかにも言語を学んでいる感じがする。一般的に言語を学ぶというと、日本語とか英語とか、そういう人間が使う言語を勉強しているように聞こえる。僕だって誰かが「言語を勉強してるんです」と言っていたら、「何語を勉強しているんですか?」と聞きたくなる。その相手が仮に日本語母語話者で、さらに「日本語です」と答えようものなら奇妙に思うだろう。
(7) その途中の作業の効率化もできれば、分析の手順を明示的に記述もできて再現性が高くメリットが多い。また、実際に理論を動かして遊べて、新しい発見もあった。
-
- 2023年10月03日 『10月からの新連載』
-
7月から12回にわたり、「ウクライナ・ロシアの源流―スラヴ語の世界」と題して、ウクライナ戦争で世界から注目されるようになったスラブ語圏について言語の観点から迫ってくださった渡部先生、ありがとうございました。来年刊行予定の新書では新たな話題も盛りこまれるとのことです。ぜひ、新書にもご注目ください。
さて、10月10日からの12回の連載は岸山健先生(法政大学文学部英文学科ほか非常勤講師)による「言語学闇鍋エンジニアリング」です。岸山先生は心理言語学や計算言語学の研究をされており、現役のエンジニアとしても活躍されています。また、著書に弊社から出版の『jsPsychによるオンライン音声実験レシピ』があります。この連載では、言語にまつわるネットに出回っていない話を、計算機を使ったシミュレーションと一緒に紹介されます。コンピューターを使えない方も9割は楽しめる内容になるとのことですので、ご期待ください。(野口)