あたらしい漢字指導のカタチ 外国にルーツを持つ児童生徒が学ぶために(kotoba news)
kotobaに関する気になるトピックを短期連載で紹介していきます。
-
- 2021年08月10日 『あたらしい漢字指導のカタチ―外国にルーツを持つ児童生徒が学ぶために 6. 学習者による字形分解 本多由美子(国立国語研究所)』
-
1.はじめに
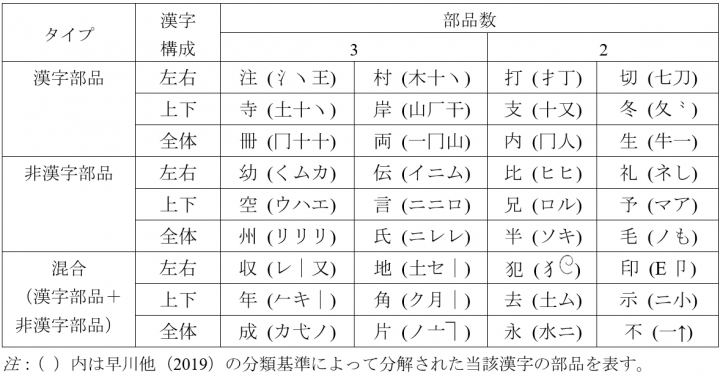 表1: 調査に用いた漢字 (N=36) (第5回 表1)
表1: 調査に用いた漢字 (N=36) (第5回 表1)
 図1: 学習者による漢字分解例
図1: 学習者による漢字分解例
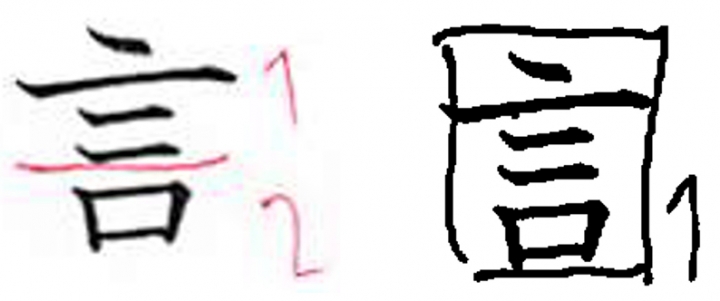 図2: 同じ学習者の「言」の分解例(左:1回目、右:2回目)
図2: 同じ学習者の「言」の分解例(左:1回目、右:2回目)
 図3: 表1よりも学習者による部品数のほうが少ない漢字分解例
図3: 表1よりも学習者による部品数のほうが少ない漢字分解例
 図4: 「永」の分解例
図4: 「永」の分解例
 図5: 「氏」の分解例
図5: 「氏」の分解例
第5回では、早川他(2019)の新しい漢字分解のアプローチが外国にルーツを持つ児童生徒の漢字の視認性を高めるのかを明らかにする過程で行なった、予備実験を紹介しました。この予備実験では、成人の日本語学習者を対象に実験を行った結果、「漢字部品/非漢字部品」の分類が非漢字圏の日本語学習者の漢字認識に多少なりとも影響を与えていることがわかりました。
今回は、この実験結果を踏まえ、学習者自身に実際に字形分解をしてもらった調査の結果を紹介します。この調査は第5回で紹介した再認実験に続けて行った調査で、第5回の実験と同じ学習者によるものです。今回の内容の一部は早川他(2021)、早川・本多(2021印刷中)をもとにしています。
2.調査の背景
2.1 これまでの実験の結果からわかったこと
前回紹介した実験は、まず、実験参加者に漢字のリストを渡して覚えてもらい(記憶課題)、次に、リストを見ずに、パソコンにランダムに提示される漢字がリストに記載されていたかどうかを、できるだけ速く正確に回答し(再認課題)、その答えにかかる時間と正確さを測定するというものでした。この実験は、漢字を15字学んだ漢字学習の開始時期(1回目)と、130字程度の漢字学習を終えた時期(2回目)に2回行い、両者の結果を比較しました。比較の結果、2回目のほうが、調査対象の漢字に対して字形認識のスピードが上がったことがわかりました。また、「漢字構成(左右型・上下型・全体型)」の条件で結果を比較すると、左右型よりも上下型と全体型のほうが早く字形を認識できるようになっていたこともわかり、漢字構成と字形の認識には何らかの関係があることが示唆されました。
2.2 日本語学習者にとっての字形分解
前回の実験に利用した「漢字構成(左右型・上下型・全体型)」の分類は、齋藤他(2003)に準じました。齋藤他(2003)は、JIS第一水準の漢字2,965字を厳密な規則にしたがって分解し、分類していますが、これは、数千の漢字の全体像を把握したうえで行なったものです。これに対し、実験参加者である非漢字圏の日本語学習者は、漢字の学習を始めたばかりであり、授業で示される漢字の字形を1字ずつ覚えていきます。漢字構成について明示的な指導も受けていません。そのため、学習者が漢字の分解をした場合、分解のしかたは、筆者らが設定した漢字構成とは一致しないものもあると思われます。また、一定の学習期間を経て、字形の分解の仕方が変化するかどうかも興味深い点です。
このような関心から、学習者に意識的に漢字を分解してもらい、その結果を前回の実験結果と比較することにしました。
3.調査の方法・手順
3.1 調査協力者
調査協力者は、第5回で報告した実験に参加した、日本国内の大学で学ぶ非漢字圏の日本語学習者12名です。実験終了後、そのまま今回の調査に協力してもらいました。1回目の調査は、ひらがな、カタカナの学習が終了し、漢数字などの漢字を15字程度学んだところで行いました。2回目の調査は漢字を約130字学んだところで行いました。
3.2 調査に用いた漢字
調査には第5回の実験に使用した36字を用いました(表1 クリックして拡大)。この表は早川他(2021)をもとに一部改変したものです。選定方法の詳細は、第5回をご覧ください。この36字は、第1回目の調査のときは、すべてが授業で教えていない漢字でした。2回目の調査のときは36字のうち、4字(生、言、半、年)は授業で扱っていました。漢字構成では、左右型、上下型、全体型がそれぞれ12字あります。なお、第5回の実験で報告した反応時間の結果においては、2回目の分析にあたって、学習した4字を除外した場合と除外しなかった場合の両結果を比べてみましたが、学習した4字が含まれた場合と、除外された場合とで結果は変わりませんでした。反応時間の観点から言えば、この4字の学習経験の影響は限定的であると考えられます。
3.3 調査方法
第1回目、第2回目ともに同じ方法で実施しました。実験が終了した直後に、学習者に表1の漢字が記載されたリストを渡して、漢字は複数の構成要素から成り立っていることを説明し、覚えやすいように漢字を分解するならどのように分けるかを自由に記入してもらいました。図1(クリックして拡大)は学習者の分解例です。
4.結果と分析
分析結果については、①第5回の実験結果と本調査結果との比較、②1回目と2回目の調査の間に授業で扱った4字(生、言、半、年)の分析、③早川他(2019)の分類基準による分解と学習者の分解との比較の3つを紹介します。①と②は、学習時期という観点を入れて分析したもの、③は、表1の部品数との比較を通して、学習者による字形の捉え方の一部を概観するものです。なお、①②は早川他(2021印刷中)をもとにしています。
4.1 実験結果との比較*1
ここでは、まず、学習者の漢字分解の回答を「(当該漢字を)分解したか/分解しなかったか」に分けて分析を行いました。例えば、図1では、「兄」は「分解しなかった」、「礼」「両」は「分解した」に分類しました。「両」のように3つ以上に分解した場合もすべて「分解した」に分類しました。
次に、学習時期(開始時:1回目、終了時:2回目)と漢字構成ごとに、各学習者が漢字を分解した割合を求めました。これ以降この割合を「分解率」と呼びます。漢字構成の左右型、上下型、全体型はそれぞれ12字です。例えば、ある学習者が学習開始時に、上下型の漢字12字のうち、9字を分解し3字を分解しなかった場合、この学習者の学習開始時における上下型の分解率は75.0%です。
各学習者の分解率を用い、漢字構成と学習時期を条件として、統計的な手法で分析を行いました。本稿では、分析手法等の詳細は割愛しますが、分析した結果、学習時期による分解率に統計的な差は見られませんでした*2。一方、漢字構成による分解率には統計的な差が見られました。漢字構成についてさらに詳しく分析したところ、分解率は高い順に、左右型、上下型、全体型であることがわかりました。つまり、左右型、上下型、全体型という3つの型の中で、左右型は複数の形態に分けられる傾向が最も強く、全体型はひとまとまりの形態として捉えられる傾向が最も強いことが示唆されました。
第5回の実験結果では、上下型や全体型よりも、左右型の漢字のほうが字形を認識する時間が長かったという結果が得られました。これについて、左右型の漢字は、上下型・全体型よりも、部品と部品の間の余白が比較的大きく見えるため、左右に分かれた細部の形態特徴への注意が必要となり、正確に認識するのにやや時間がかかると考えられることを指摘しました。今回の調査結果でも、左右型が最も分解されやすいという結果が得られました。
第5回の実験結果と、今回の学習者による意識的な分解の結果は見ているものが異なりますが、字形を認識することや字形を分解することと、漢字の漢字構成とには何らかの関係があるのではないかと思われます。
4.2 授業で扱った4字についての分析
1回目と2回目の調査の間に授業で扱った漢字は4字(生、言、半、年)ありました。1回目と2回目の分解率に統計的な差は見られませんでしたが、この4字を取り出して、漢字ごとに分解した人数(実験参加者12名中何名が分解したか)を集計したところ、4字すべてではありませんが、学習開始時と終了時とで、分解した人数が減少した漢字がありました。
分解した人数を「学習開始時→終了時」で示すと、「言」8名→3名、「半」8名→1名、「年」4名→3名、「生」3名→4名でした。「言」は点画の間に空間が多い漢字です。1回目では半数以上の人が「言」を分解しましたが、2回目で分解した人は3名で、1まとまりの形態として捉えた学習者が増えました。図2(クリックして拡大)は同じ学習者の1回目(左)と2回目(右)の回答です。
「年」や「生」は1回目と2回目では、分解した人数はほぼ同じです。しかし、1回目で分解した人が「年」は4名、「生」は3名であり、半数以下です。このことから「年」や「生」は、もともと1まとまりで捉えられる傾向のある漢字だと考えることもできます。これについては、データを増やして検討する必要がありますが、学習した漢字を1つの形態として捉える傾向が強まることは、早川他(2019)で既知の形態を1つの部品とするという考え方と重なるものだと思われます。
4.3 早川他(2019)の分類基準による分解と学習者による分解との比較
早川他(2019)の分解の仕方と、学習者による分解の仕方を比較するために、表1で示した部品数と、漢字の知識がほとんどない状況の1回目の調査で、学習者が分解した部品の数とを比較しました。例えば、図1の学習者が分解した「礼」「兄」「両」の部品数はそれぞれ2、1、3です。表1(早川他2019)の「礼」「兄」「両」の部品数は2、2、3ですから、「兄」は表1よりも学習者のほうが部品数が少ない例です。「礼」と「両」は学習者と表1の部品数が同じ例です。早川他(2019)は子どもによる字形の認識を念頭に置いたものであり、本調査で成人の学習者が意識的に字形を捉えた結果とは必ずしも一致しないと思われますが、比較を通して、成人の非漢字圏学習者の字形の捉え方の一部を紹介したいと思います。
表1の部品数と学習者12名全員の分解による部品数を集計したところ、両者が同じだった漢字は「礼」「切」「打」の3字でした。この3字はいずれも部品数が2の左右型の漢字です。学習者全員の回答が部品数だけでなく、部品の形も同じでした。
それ以外の漢字については、表1の部品数よりも学習者による部品数のほうが少ない、つまり、1回目の調査においては、学習者は表1に示した部品よりも大きな形態に字形を分解する傾向があることがわかりました(図3)。例えば、「収」と「村」は、表1の部品は「レ|又」と「木十丶」ですが、学習者は全員、左右の2つに漢字を分解しています。また、「幼」は表1では「くムカ」ですが、左右2つに分解した学習者は10名でした(図3 クリックして拡大)。これらの漢字は左右型の漢字で、部品を分ける細かさによって、表1と学習者とで部品数に違いが表れたものと思われます。
反対に表1の部品数よりも学習者の分解による部品数のほうが多い漢字はほとんどありませんでした。「永」は表1では部品数2の漢字ですが、学習者の結果を見ると、部品数3の学習者が12名中6名、部品数2の学習者が5名、部品数1の学習者が1名おり、表1のよりも細かく分解した学習者が多く見られました(図4 クリックして拡大)。「永」の部品は表1では「水ニ」ですが、学習者は「水」を習っていないため、様々な分解例が見られました。図4の左2つは部品数が3、一番右は部品数が2の例です。未習の状態では形態間の空間にしたがって字形を分解していることが見て取れます*3。このような結果は漢字のシラバスにおいて提出順を決める際に参考にできる情報だと思われます。なお、36字のうち、表1よりも細かく分解される傾向にあった漢字は「永」のみでした。
また、部品の取り出し方が表1と学習者とで大きく異なるものに、「氏」があります(図5 クリックして拡大)。表1では、「氏」は全体型で部品は「ニレレ」ですが、学習者の中で同じように分解した人はいませんでした。「氏」は「永」のような形態を分ける空間がありません。学習者の回答では、図5の一番左と中央の漢字のように左右で分解する場合と、一番右の漢字のように分解しない場合とが見られました。左右で分解している一番左と中央の漢字を比べると、一番左の漢字は、数字の「1」が左側の部品に振られていますが、中央の漢字は右側の部品に振られています。これは、それぞれの「1」の形態が、分解した学習者にとって部品として取り出しやすかったのだと思われます。
5.今後の展望、課題
今回は、非漢字圏の学習者自身に実際に字形分解をしてもらった調査結果を紹介しました。まず、第5回で報告した実験結果との比較では、第5回の実験結果と学習者による字形分解の結果はいずれも漢字構成との間に関係が見られた点を指摘しました。次に、既習の漢字は1まとまりの形態として捉えられやすい可能性があることを述べました。そして、早川他(2019)の字形分解と、学習者による字形分解を比較し、両者の相違点から学習者による字形分解の一部を概観しました。字形の分解は、人によって部品の大きさや数が異なる場合もありますが、多くの人で一致する場合もあると思われます。今回の調査結果からも、漢字の構成では、特に左右型が成人の非漢字圏学習者には分解されやすいということは言えそうです。
今回の調査は画数や部品数が比較的少ない少数の漢字を用いて実施したものです。調査に用いた漢字のフォントも結果に影響を与える可能性があります。したがって、今回の結果をもって一般性のある傾向が述べられるものではありません。しかし、小規模でも試行と検証を繰り返すことによって、母語の文字体系に漢字を持たない学習者の字形認識や、字形の覚えやすさなどに関する知見が蓄積されていくものと思います。
早川他(2019)の「漢字部品/非漢字部品」は暫定的なものなので、外国にルーツを持つ児童生徒の漢字指導に役立てることを目標に、今後も様々な角度から調査、検討を重ねていきたいと思います。
これで、6回の連載を終わります。非漢字圏の学習者(特に子ども)にとって、日本語習得の鍵が漢字にあることは間違いない事実です。日本語母語話者は自らの習得経験に基づいて漢字を考えがちですが、来日まで漢字にほとんど触れたことがない非漢字圏の子どもにとっては、漢字のイメージはそれとは大きく異なる可能性が高いと考えられます。
今回の連載で述べてきた調査や実験は、そうした違いを想定しながら、いかに漢字学習、ひいては日本語学習の壁を低くするかという問題に関する私たちの答えの一部です。問題は決して簡単ではなく、まだまだ試行錯誤を続ける必要がありますが、問題の重要性、緊急性を念頭に、これからも研究を続けていきたいと思います。
引用文献
齋藤洋典・川上正浩・増田尚史・山崎治・柳瀬吉伸(2003)「JIS第一水準に属する漢字2,965字に対するN次分割による抽出「部品」の結合特性」科学研究費報告書『意味処理における情報統合過程の解明』
早川杏子・本多由美子・庵功雄(2019)「漢字教育改革のための基礎的研究—漢字字形の複雑さの定量化」 『人文・自然研究』 (13) 116-131,一橋大学. https://hermes-ir.lib.hit-u.ac.jp/hermes/ir/re/30146/jinbun0001301160.pdf
早川杏子・本多由美子・庵功雄 (2021)「非漢字圏日本語初級学習者を対象とした漢字字形認知に関わる予備的実験−漢字学習開始時と終了時における再認実験から」『人文・自然研究』15, 141-153, 一橋大学. https://hermes-ir.lib.hit-u.ac.jp/hermes/ir/re/71656/jinbun0001501410.pdf
早川杏子・本多由美子(2021印刷中)「漢字字形の特徴が非漢字圏初級日本語学習者の漢字認識処理に与える影響:漢字学習前後における処理傾向の比較分析」李在鎬(編)『データ科学×日本語教育』ひつじ書房,2021年10月刊行予定.
*1 この分析は早川他(2021印刷中)の内容をもとにしています。詳細はそちらをご参照ください。
*2 分析の詳細は早川他(2021印刷中)をご参照ください。
*3 「水」を分解せずに1まとまりの形態として捉えた人は1回目の調査では2名、2回目の調査では6名でした。
-
- 2021年08月03日 『あたらしい漢字指導のカタチ―外国にルーツを持つ児童生徒が学ぶために 5. 漢字分解に関する予備的実証実験と漢字字形の順序づけ試案 早川杏子(一橋大学)』
-
1.はじめに
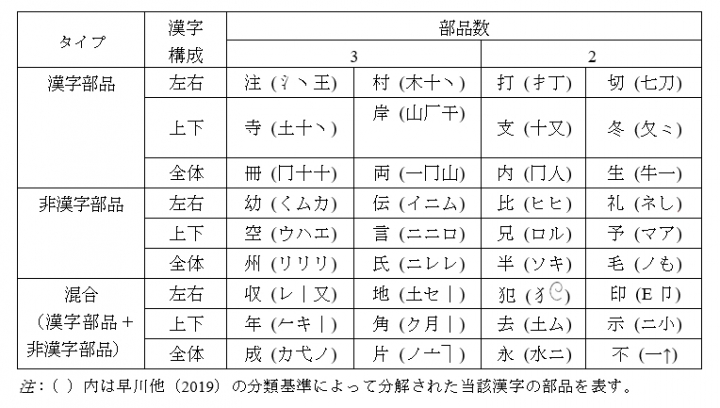 表1: 実験対象の漢字 (早川他(2021)をもとに一部改変)
表1: 実験対象の漢字 (早川他(2021)をもとに一部改変)
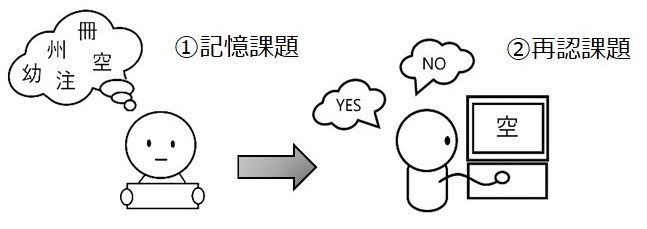 図1: 実験の流れ(早川他(2021)をもとに一部改変)
図1: 実験の流れ(早川他(2021)をもとに一部改変)
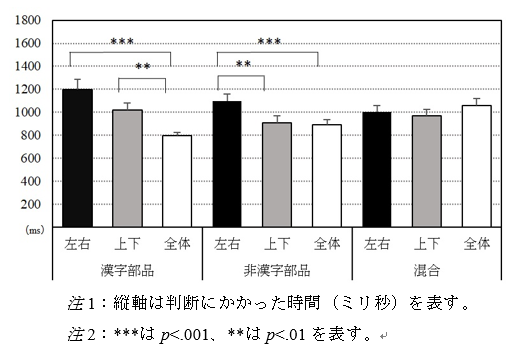 図2: 「漢字部品/非漢字部品」☓「漢字構成」の組み合わせによる結果(早川他 2021)
図2: 「漢字部品/非漢字部品」☓「漢字構成」の組み合わせによる結果(早川他 2021)
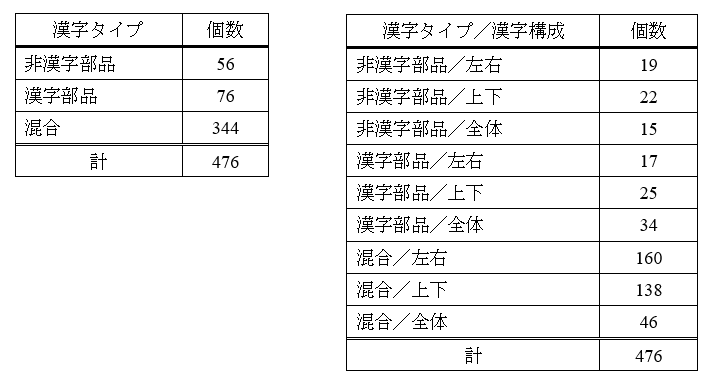 表2: 漢字部品上位30と非漢字部品57の組み合わせにより字形認識が可能になる教育漢字476字の漢字タイプと漢字構成の個数 (早川他(2021)をもとに一部改変)
表2: 漢字部品上位30と非漢字部品57の組み合わせにより字形認識が可能になる教育漢字476字の漢字タイプと漢字構成の個数 (早川他(2021)をもとに一部改変)
第4回では、外国にルーツを持つ児童生徒への漢字の字形学習の負担を軽減し、漢字の視認性を高めるために、彼/彼女らにとって認識がしやすいかどうか、覚えるべき構成要素をできるだけ少なくすることを重視した、早川他(2019)の新しい漢字分解のアプローチをご紹介しました。この漢字分解では、既知の形態を積極的に取り入れた非漢字部品と頻度の高い形態などを含む漢字部品に分類され、教育漢字1,006字は計158の部品に分けられました。そして、この非漢字部品57個と、漢字部品の上位30を組み合わせると、教育漢字1,006字の47.3%に当たる476字の漢字がカバーできることがわかりました。
教育漢字1,006字の半数弱をカバーできることがわかったとはいえ、この分解方法で分類した部品が果たして外国にルーツを持つ児童生徒の漢字の視認性を高めるのか、という疑問が生じます。そこで、上記の疑問に対する予備的な実証実験である(早川他2021)の概要をご紹介します。
2. 漢字の分解
2.1 漢字の構成
前回も少し触れましたが、漢字を分解する試みは目新しいものではありません。齋藤他(2003)は、人のメンタルレキシコン内では、何らかの情報が付与された形態的なまとまりの部分集合が結合することで漢字が認識されると仮定して、JIS第一水準の漢字2,965字を、厳密な分割規則にしたがって分解しています。初めに、齋藤他(2003)は漢字を二分割できるかどうかという基準で漢字を分けました。その結果、漢字は左右(例:政)、上下(例:星)、囲い込み(例:団、送)の3つのタイプに分割することが可能で、2,965字のうち2,793字(94.2%)を占めました。一方、分割できない漢字(例:成)は172字(5.8%)でした。
齋藤他(2003)は日本語母語話者の心内で漢字がどう表されているのかを明らかにする目的で漢字を分解しましたが、第二言語として日本語を学ぶ非漢字圏学習者の視点から漢字字典を編纂したHalpern(1990)でも、漢字の構造を左右・上下・囲み・全体型の4タイプに収束させました。漢字字形の特徴を捉えようとする時、大きくこの4パターンになることは一定程度、合理性を持っていると考えられます。
2.2 漢字部品、非漢字部品
齋藤他(2003)は、JIS第一水準の漢字2,965字を対象に、分割できるか/できないかを判定しました。齋藤他(2003)では、分割できる漢字の場合は分割を繰り返し、分割後の部品がJIS第一水準内の漢字と同形か否かに分類してから、JIS第一水準内の漢字として同形のものを「漢字部品」、JIS第一水準内の漢字として同形ではないものを「非漢字部品」と分類しました。例えば、「星」は分割すると「日」と「生」に分けられます。「日」も「生」もJIS第一水準の漢字に同形の漢字があるので、両方とも「漢字部品」です。一方、「政」を分割すると「正」は漢字部品ですが、「攵」はJIS第二水準に登録されてはいるものの、第一水準内の漢字には同形の漢字がないので、「非漢字部品」です。
早川他(2019)が行った教育漢字1,006字の漢字分解でも、学習者がわかりやすいように、ギリシャ数字の「Ⅱ」のような漢字としてはみなされない部品を「非漢字部品」、漢字に帰属する部品を「漢字部品」と呼んでいますが、齋藤他(2003)の指す「漢字部品/非漢字部品」とは定義が異なります。早川他(2019)が指す「漢字部品」の中には、「扌」のように頻度の高い部首などが含まれますが、齋藤他(2003)では「扌」は「非漢字部品」に分類される、といったように分類は必ずしも一致しないことに注意してください。
3. 漢字字形認知に対する予備的実験
3.1 予備実験の仮説
今回ご紹介する実験の目的は、早川他(2019)が分解した漢字部品が外国にルーツを持つ児童生徒の漢字の視認性を高めるのか、という問いを解決することでした。実験的な研究を行う場合、協力してほしい対象者に直接実験を行う前に、実験の測定効果を確かめるため、予備実験を行うことがあります。この予備実験もその目的で、漢字を母語の表記として用いない点で外国にルーツを持つ児童生徒と近似した背景を持つ成人の日本語学習者に対して行いました。
上記の問いを明らかにするために、3つの条件を設定しました。一つ目は、早川他(2019)の「漢字部品」と「非漢字部品」の条件です。早川他(2019)の「非漢字部品」が認識しやすい形であった場合、「漢字部品」よりも、速く形が捉えられるはずです。それならば、「非漢字部品」だけで構成される漢字は、「漢字部品」だけで構成されるものより、字形処理のスピードが速いと予測されます。また、「漢字部品」と「非漢字部品」が組み合わさった漢字(このタイプを「混合」とします)の場合はどうなるかわからないので、これも検討に入れます。
二つ目の条件は、漢字構成です。漢字は小さな部品集合の構成の違いによって、大きく4つに分けられそうだということを2節で述べました。字形の認識プロセスを考えると、大まかな外形的な特徴を捉えるという認知的働きが関与すると考えられます。そこで、齋藤他(2003)の漢字構成(4タイプ)も学習者の字形処理に何らかの影響を及ぼすと仮定しました。
三つ目は、漢字学習経験の条件です。漢字という未知の文字の学習を開始した時点と、ある程度漢字学習を経た時点では、漢字の認識のしかたが変わっているかもしれません。
予備実験では、以上の三点を考慮して漢字の選定や実施計画が立てられました。
3.2 実験対象の漢字
実験に用いられたのは、36字(表1 クリックして拡大)です。「漢字部品/非漢字部品/混合」で成り立つか、漢字構成が「左右/上下/全体」型かで条件づけされています。なお、ここでの「全体」は齋藤他(2003)の「囲い込み」と「全体」の両方を含んでいます。教育漢字全体の中で、「囲い込み」の数は少ない上*1、部品の空間配置上、「全体」と近似しているからです。
表1の漢字の横にある( )内の形は、その漢字を分解した場合の部品です。また、表1の上の欄に「部品数」という情報があります。これは、あまりに部品数が多く形が複雑だと、参加者が時間内に覚えることができない可能性があるので、漢字を分解した際に分けられる部品数が2~3のもののみを選びました。
3.3 対象者
実験に参加したのは、日本語を第二言語として学ぶ大学生12名です。全員欧米や東南アジア出身で、非漢字圏に属し、一から日本語を学ぶ入門レベルのコースに所属していました。1回目の実験を行った時、実験に参加した学生たちは、ひらがなとカタカナの学習を終え、ちょうど漢数字「三、十」などを中心とした15字*2を学んだところでした。そして、2回目の実験時には、130字程度の漢字学習を終えたところでした。この学生たちは、授業においてそれぞれの漢字の読み書きができることを目指した、ごく一般的な方法で漢字を学び、早川他(2019)の「漢字部品/非漢字部品」、齋藤他(2003)の漢字構成の分類に関する知識は一切持ち合わせていませんでした。
4. 実験方法と結果
4.1 方法
実験は、リストの漢字を覚える「記憶課題」の後、前のリストを見ずに、パソコンでランダムに提示される漢字がリストにあったどうかを答える「再認課題」という方法で行いました*3。再認課題というのは、先に提示された情報があったかなかったかの判断をパソコンの指定のボタンを押して回答するシンプルなものです。この種の実験では、この判断に要する時間が学習者の心内で字形認識される速さを反映しているとみなして、ボタンを押すまでの時間と正確さを基準に結果を解釈します。(図1 クリックして拡大)
4.2 結果
まず、三つ目の条件である漢字学習経験ですが、1回目より2回目のほうが判断に要する時間が有意に短く*4、漢字の学習経験が非漢字圏出身である日本語学習者の漢字字形処理を促したと考えられます。しかしながら、一つ目ならびに二つ目の条件である「漢字部品/非漢字部品」、「漢字構成」の条件においては、1回目と2回目では傾向は変わりませんでした。つまり、漢字学習前と学習後では、先のリストで覚えた漢字の字形認識のスピードは上がったのですが、対象語が持つ「漢字部品/非漢字部品」や「漢字構成」の特徴から受ける影響は学習前後で変わらなかったということです。
次に、「漢字構成」条件では、左右型よりも、上下型・全体型が有意に判断時間が短くなっていました。左右型の漢字は、上下型・全体型よりも、部品と部品の間の余白が比較的大きく見えます。そのため、左右に分かれた細部の形態特徴への注意が必要となり、正確に認識するのにやや時間がかかるのだと考えられます。
そして、「漢字部品/非漢字部品」の条件ですが、「漢字部品/非漢字部品/混合」から成る漢字の間に、判断に要する時間に有意な違いはみられませんでした。ただ、「漢字構成」との組み合わせ条件において、それぞれに違う特徴がみられました。
その「漢字部品/非漢字部品」と「漢字構成」を組み合わせた場合の反応時間の比較を図2に表してみました。漢字部品(例:注、内)の場合、全体型が最も判断にかかる時間が短く、左右型、上下型よりも有意に速く処理されていました。それに対し、非漢字部品(例:州、予)の場合では、上下型と全体型はほとんど判断時間が変わらず、左右型が有意に時間がかかっていました。また、混合(例:犯、不)の漢字の場合は、漢字構成の異なる漢字の間に有意な違いがなかったことがわかりました。漢字構成それぞれにあった字形の認識を促す効果が、混合においては互いに打ち消し合ってしまったと推察されます*5。(図2 クリックして拡大)
漢字部品、非漢字部品のみから成る漢字に少し違った傾向がある理由を特定するのはこの実験からだけでは難しいのですが、部品×漢字構成を組み合わせた特徴が、多かれ少なかれ非漢字圏出身の日本語学習者における漢字の字形再認処理に作用する、ということはどうやら言えそうです。まとめると、漢字を母語の文字としない日本語学習者は漢字の字形を認識するために、構成要素の形態的特徴や余白などの空間性の情報を利用しているようですが、その情報の利用のしやすさに違いがあるのではないかと筆者たちは考えています。
5.外国をルーツに持つ児童生徒に対する漢字字形の順序づけ試案
早川他 (2019)では、上位30の漢字部品と57の非漢字部品の組み合わせによって、教育漢字1,006字のうち、47.3%(476個)の漢字の字形認識が可能になると推定しています。そこで、この476個の漢字に対して、漢字部品/非漢字部品/混合か、どの漢字構成(左右、上下、全体)かという情報を付与したところ、結果は表2(クリックして拡大)のようになりました。
今回の実験結果の範囲で漢字導入の順序を示すとするなら、まず、全体型から学習するのがよいのではないかと考えます。その理由は、全体型は漢字部品、非漢字部品の両漢字タイプにおいて最も処理が速かったからです。このタイプは、「内」や「不」のように対称性が高いものが多く、認識が比較的容易なのでないかと思われます。
その次は、非漢字部品のみで構成される漢字を、上下型→左右型の順で教えるとよいかもしれません。上下型は、左右型よりも比較的速く処理されており、部品の空間配置に規則性があります。そのため、漢字の基本的な空間配置に意識を向けやすくなります。非漢字部品は、一から学習する必要がなく学習者の認知的負荷が低い形態であるため、漢字部品のような新たな形態特徴にとらわれることなく、部品の空間的な配置に注意を向けさせやすいはずです。
そして最後に、漢字部品・非漢字部品が組み合わされた混合の漢字ですが、このタイプの漢字は数が最も多くなっています。そのため、学習順序としては最後に回し、全体型→上下型、左右型の順で学習していくとよいのではないでしょうか。ただ、上下型と左右型どちらも同じぐらい数があるので、どのような順序で配列すべきか、さらに検討していく必要がありそうです。混合といっても、漢字を構成する部品数など、さまざまなバリエーションがあるので、より詳細に検討を重ねていくことで、漢字シラバスの順序づけができていくだろうと思います。
6. 今回のまとめと次回の予告
今回では、早川他(2019)の新しい漢字分解のアプローチがはたして外国にルーツを持つ児童生徒の漢字の視認性を高めるのか、という疑問を明らかにするために、漢字を母語の表記として用いないという点で彼/彼女らと近似した背景を持つ成人の日本語学習者に対して行った、漢字の予備実験をご紹介しました。その結果をもとに、漢字指導の導入順序に対する試案を示しました。
前回述べたように、「漢字部品/非漢字部品」は暫定的な分類であり、導入順序の試案についてもさらなる検討が必要です。また、この予備実験は成人の日本語学習者を対象としていることから、今後は児童生徒に対する実証を重ねていく必要があります。
今回の予備実験では、「漢字部品/非漢字部品」の分類が非漢字圏の日本語学習者の漢字認識に多かれ少なかれ影響していることはわかりましたが、分解した各部品が日本語学習者が漢字を覚える際に覚えやすい形態であるのかどうかまではわからず、課題が残ります。
そこで次回は、これから分類を精緻なものとするための一つのヒントとして、実験に参加してもらった日本語学習者自身が漢字を分解したデータの分析結果をご報告します。
引用文献
齋藤洋典・川上正浩・増田尚史・山崎治・柳瀬吉伸(2003)「JIS第一水準に属する漢字2、965字に対するN次分割による抽出「部品」の結合特性」科学研究費報告書『意味処理における情報統合過程の解明』
早川杏子・本多由美子・庵功雄(2019)「漢字教育改革のための基礎的研究―漢字字形の複雑さの定量化」 『人文・自然研究』 (13) 116–131,一橋大学. https://hermes-ir.lib.hit-u.ac.jp/hermes/ir/re/30146/jinbun0001301160.pdf
早川杏子・本多由美子・庵功雄(2021)「非漢字圏日本語初級学習者を対象とした漢字字形認知に関わる予備的実験-漢字学習開始時と終了時における再認実験から」『人文・自然研究』15, 141-153, 一橋大学. https://hermes-ir.lib.hit-u.ac.jp/hermes/ir/re/71656/jinbun0001501410.pdf
Halpern, Jack(1990)New Japanese-English Character Dictionary. Kenkyusha.
*1 教育漢字1,006字のうち、「囲い込み型」は104字(10.3%)、「全体型」は108字(10.7%)です。
*2 15字の内訳は、「一」~「十」、「百、千、万、円、時」でした。
*3 実験参加者は、本番に入る前に、学習したばかりの「二、六」などの漢数字を用いて、本番と同じ手順で十分な練習を行いました。
*4 分析は統計的処理を行っています。統計的に「有意である」(significant)というのは、確率的に偶然とはいえない水準である事象が生じたとみなす考え方です。
*5 実験についての詳細は、早川他(2021)をご覧ください。
-
- 2021年07月27日 『あたらしい漢字指導のカタチ―外国にルーツを持つ児童生徒が学ぶために 4. 字形学習の負担を軽減するための字形分解 本多由美子(国立国語研究所)』
-
1.はじめに
第3回では、漢字は「形(書字)」「読み(音韻)」「意味」の3つの情報を合わせ持つ「語」であり、漢字指導においてはこれらの情報を考慮する必要があることを述べました。また、外国にルーツを持つ児童生徒への漢字指導においては、優先度を考慮した漢字シラバスが有用であることを指摘しました。そして、優先度という考えに基づいて漢字の読みを絞る取り組みとして、中学校の教科書における漢字の読み頻度の調査および分析結果を紹介しました。
今回は漢字の持つ3つの情報の中で「形」、すなわち漢字の字形を取り上げます。以下、外国にルーツを持つ児童生徒の字形学習の負担を軽減するために、私たちが取り組んでいる教育漢字を対象にした漢字分解の試みを紹介していきます*1。
2.外国にルーツを持つ児童生徒と字形学習
アルファベット文字と比べたときの漢字の字形の特徴は、「点画(筆画)の多さ・複雑さ」と「構造性」が挙げられます(日本語教育学会編2005)。ほぼすべての漢字は複数の線や点から成ります。また、「体」という漢字は「亻」と「本」、「暑」という漢字は「日」と「者」から成るというように、多くの漢字では、いくつかの線が集まった小さな形態が組み合わさって1つの字を形成しています。
小学校1年生から学ぶ、日本語母語話者の子どもは、象形文字(例 山、木)や、指事文字(例 上、中)のような単純な構造の字形の学習から始め、偏や旁などの構成要素を含む複雑な字形の漢字を学んでいきます。他方、外国にルーツを持つ児童生徒は、小学校の途中から編入する子どもの場合、毎日の学校生活や学習で目にする漢字から理解する必要性が生じます。日々遭遇する漢字は体系的な順序で示されるものではありません。また、これまでに述べてきたように、限られた時間の中で大量の漢字を覚えなければならない状況にもあります*2。このように考えると、外国にルーツを持つ児童生徒に対する漢字指導では、特に日本語学習の入り口の段階で、字形の複雑さによる学習の負担をいかに減らすかが重要になると思われます。
では、彼/彼女らの字形学習の負担をどのように軽減すればよいでしょうか。私たちは、漢字の視認性を高めることが字形学習に寄与すると考えました。ここでの「漢字の視認性」とは、「字形を視覚的に同定できること」という意味で用います。
3.字形分解の先行研究と新たなアプローチの必要性
これまでの研究でも、日本語学習者の漢字学習を支援する目的で、漢字の字形を分解したり、パターン化したりする試みが行われてきました(Halpern1990,ヴォロビヨワ2014など)。しかし、研究者がそれぞれ独自の基準をもとに構成要素を定めており、構成要素のスタンダード化は行われていません(ヴォロビヨワ, 2014:26)。これらの研究では、筆画や部首などにコードを振り、字形の筆画や筆順、構造を明確に示す工夫がなされています(ヴォロビヨワ2014、ヴォロビヨワ&ヴォロビヨフ2015)。
例えば、ヴォロビヨワ(2014)では、アルファベット・コード、シンボル・コード、セマンティック・コードの3つが設定されています。アルファベット・コードは、筆画に振られたコードで、常用漢字2,136字をカバーする筆画が24種類定められています(図1 クリックして拡大)。シンボル・コードは、部首と準部首(部首に準じる形態)が番号で示されたものです。部首は『康煕字典』に掲載されているもの、準部首は独自に定められたもので「最小意味的単位」(ヴォロビヨワ2014:99)とされています。図2(クリックして拡大)は、常用漢字に含まれる105個の準部首です。また、セマンティック・コードは構成要素の意味の情報を表します。
これらのコードを用い、ヴォロビヨワ(2014)では、「鱗」という漢字の構造を図3のように示しています。アルファベット・コードには筆画を表すアルファベットが筆順に並んでいます。シンボル・コードの3つの数字は、それぞれ「魚」「米」「舛」につけられたコードです。セマンティック・コードの「fish/rice」はそれぞれ「魚」「粦」を表します。
・漢字構造の公式「鱗=魚+粦(米+舛)」
・アルファベット・コード「PYBHBAALQQQQLABPOPYQABAB」
・シンボル・コード「195/119/136」
・セマンティック・コード「fish/rice」
図3 「鱗」の漢字構造の公式およびコード(ヴォロビヨワ2014:44)
ヴォロビヨワ(2014)の分析は精緻であり、大学で学ぶ学習者など、コードの処理に慣れた学習者にとっては、漢字の構造の把握が促されるものですが、子どもの学習者には、やや複雑だと思われます。また、ヴォロビヨワ&ヴォロビヨフ(2015)では、常用漢字2,136字をカバーするシンボル・コードを307個にまとめています。これは部首202個に図2の準部首105個を加えた数です。シンボル・コードは、意味が単位の基準とされており、図2を見ると形態的には単純とは言えないものも含まれています。教育漢字の「拝」「夜」「重」なども1字で1つの準部首とみなされていますが、外国にルーツを持つ児童生徒が視覚的に形態を捉えるにはやや複雑です*3。漢字の視認性を高めるという観点からは、もう少し単純な形態に分解する必要があると思われます。
先行研究を踏まえ、私たちは彼/彼女らの日本語学習の入り口における字形学習の負担を減らすことを目標に、別のアプローチで字形分解を試みることにしました。
4.新たなアプローチ―字形を認識しやすくする字形分解の考え方
4.1 字形を認識しやすくする字形分解
外国にルーツを持つ子どもが認識しやすいような字形分解を考える際には、次の2点を重視し分解の手順を決めました*4。1点目は、「漢字が母語の文字体系にはない日本語学習者にとって認識しやすいかどうか」、2点目は「覚えるべき構成要素をできるだけ少なくすること」です。
1点目の「認識しやすさ」の基準は、線の数が少なく、外形が単純で、人間に元来備わっている形態認知能力で十分に対応可能な形であることや、学習者がこれまでの学習経験を通じて身につけた既習の表記形態であることです。そこで、認識しやすい形態として、字形分解にはひらがな、カタカナ、数字、記号や図形を積極的に用いることにしました。また、形のイメージがしやすい象形文字や指事文字も構成要素として用いることにしました。
2点目の覚えるべき構成要素を少なくすることについては、分解の際に、上述した認識しやすい形態を取り出すことを優先し、書き順には必ずしも従わなくてもよいことや、字形の外形的な特徴を失わない範囲で、ハネや払いは軽微な差として無視することなども分解の規則に取り入れることにしました。
例えば、「出」は中央を上から下まで引く縦の画があります。しかし、「出」に含まれる「山」は認識しやすい形態であるため、上下に分けて「山+山」に分解することにしました。また、「比」という漢字は左右2つの形態に分け、「ヒ+ヒ」と同じ形が2つ組み合わさったものとみなしました。「比」の筆画にしたがえば、左右の形態は異なります。以下に字形分解の例を示します。これらの分け方は、筆者らが日本語教育の現場において非漢字圏学習者の漢字学習の様子を観察してきた経験に基づきます。
出→ 山+山 左→ ナ+エ 判→ ソ+キ+リ
比→ ヒ+ヒ 南→ 十+冂+¥ 植→ 木+十+目+L
4.2 手書きを目標としない字形分解
この字形分解は漢字の視認性を高めることを目的としており、ここでは書けるようになることを目標としていません。
上の例を見て、画数やハネなどを考慮していないことに違和感を抱く方もいらっしゃるかもしれません。この字形分解の取り組みは、漢字の伝統や文化を軽んずるものではなく、母語の文字体系に漢字のない、外国にルーツを持つ児童生徒が日本語学習の入り口で、漢字を認識(字形の特徴を捉え、既知の字形であるかどうかがわかること)し、他の字形と見分けられるようになることを支援するためのものです。彼/彼女らにとって複雑だと思われる字形に既知の形態が含まれており、それらの形態を生かして漢字の字形を捉えることができれば、彼/彼女らの字形に対する心理的なハードルが少しでも下がるのではないかと思われます。入り口のハードルを下げ、その後の漢字学習につなげていくことを考えた試みです。
5. 漢字の視認性を高める部品
上述の考え方をもとに、漢字の字形分解を行い、字形の構成要素を「(1)非漢字部品」と「(2)漢字部品」という2種類に分けました。これ以降、上述の考え方に沿って取り出した字形の構成要素を「部品」と呼びます。
(1)非漢字部品
非漢字部品には、学習者が既知の知識を援用して形態を認知することが可能であるため、特別に覚える努力を必要としない形態が含まれます。①ひらがな、カタカナ、アルファベット、②数字、記号、③図形が含まれます。(表1 クリックして拡大)
(2)漢字部品
漢字部品には、①象形文字や指事文字、②形が単純で頻度の高い形態、③非漢字部品の条件に該当しない形態(例:表2 ③下線部(例えば「良」「北」))などが含まれます。
6.分解結果の量的な傾向
教育漢字1,006字*5を分解した結果、非漢字部品57個、漢字部品101個、計158個の部品に分けられました*6。非漢字部品57個(表1)と、漢字部品の上位30(表3)を組み合わせると、476字の漢字がカバーできることがわかりました。これは、教育漢字1,006字の47.3%に当たります。非漢字部品は学習者が既知の知識を援用して認識することが可能な形態であり、特別に覚える努力を必要としない形態です。新たに表3の30個の漢字部品を覚えれば、教育漢字の半数近くが認識可能(ある漢字を見てその字形に含まれる部品をすべて捉えることができる)になるという計算になります。
順位 部品
1-10位 一 日 木 十 土 目 | 小 丶 亠 11-20位 月 ? 人 氵 田 又 冂 艹 立 心 21-30位 刀 厂 大 弋 䒑 ⻎ 王 丷 夂 ?
表3 漢字部品上位30(高頻度順)
この476字それぞれの漢字を構成する部品の数をまとめると、1字あたりの部品数の平均は3.6個で、部品数が3個の漢字が最も多く、次に部品数4個の漢字が多いことがわかりました。この部品数は表1、表2の部品の数を集計したものですが、学習が進むにしたがって、既知の形態は増えていくので、1字あたり部品数は減っていくものと思われます。例えば、「音」の部品数は「立」と「日」の2つ、「暗」は「日」、「立」、「日」の3つです。「音」を先に学べば、「音」は既知の形態となり、「暗」は「日」と「音」の2つから成ると捉えることができます。
また、この476字について、学年配当をもとにそれぞれの学年の漢字に占める割合(カバー率)をみると、下の表4のようになります。例えば、476字のうち1年生の漢字は47字で、学年配当80字の58.8%です。各学年に占める割合は35~60%弱です。5,6年生が若干低いですが、これは、低学年よりも高学年のほうが字形の構造が複雑であり、他の学年では用いられていない形態の部品が多く用いられることによります。しかし、学年によって著しい偏りがないということは、外国にルーツを持つ児童生徒が必ずしも低学年に編入するわけではないことを考慮すると、どの学年から始めても本研究の部品がある程度適用できるという点で、バランスの取れた結果であると思われます。
学年 字数と割合 漢字例
1年生 47字/80字(58.8%) 右王音花貝気休玉 2年生 88字/160字 (55.0%) 園遠夏家回会絵外 3年生 98字/200字 (49.0%) 悪暗意育員央化界 4年生 105字/200字 (52.5%) 愛以衣位胃英栄億 5年生 74字/185字 (40.0%) 圧移因営易恩仮価 6年生 64字/181字 (35.4%) 域映沿株危吸筋系 計 476字/1,006字(100.0%)
表4 476字の学年配当漢字に占める割合(学年別)
7.まとめ
今回は、漢字の視認性を高めるために行った、漢字の字形分解の試みを紹介しました。字形を分解する研究はこれまでにも行われていますが、外国にルーツを持つ児童生徒にとっての認識のしやすさを仮定し、彼/彼女らの既知の形態を分解に積極的に取り入れるという考えに基づいた点が新しいアプローチであると言えます。また、分解した結果、新たに覚える必要のない非漢字部品57個に、漢字部品30個を加えることによって教育漢字の半数弱をカバーできることがわかりました。
外国にルーツを持つ児童生徒への漢字指導を考えるには、漢字の持つ「字形」「読み」「意味」の3つの側面それぞれについて検討し、その結果を統合することが重要です。今後もこれらの基礎研究を積み重ね、やさしい漢字シラバスの開発につなげたいと考えています。
今回紹介した「非漢字部品」「漢字部品」は暫定的な分類で、これからさらに検討を続けていく必要があります。次回は検討過程の1つとして、この分類の枠組みを用いて行った、非漢字圏学習者に対する実証研究をご紹介します。
引用文献
日本語教育学会編(2005)『日本語教育事典』大修館.
早川杏子, 本多由美子, 庵功雄(2019)「漢字教育改革のための基礎的研究―漢字字形の複雑さの定量化」 『人文・自然研究』 (13) 116–131,一橋大学.
https://hermes-ir.lib.hit-u.ac.jp/hermes/ir/re/30146/jinbun0001301160.pdf
早川杏子, 本多由美子, 庵功雄(2021)「非漢字圏日本語初級学習者を対象とした漢字字形認知に関わる予備的実験―漢字学習開始時と終了時における再認実験から」『人文・自然研究』 (15)141–153,一橋大学. https://hermes-ir.lib.hit-u.ac.jp/hermes/ir/re/71656/jinbun0001501410.pdf
ヴォロビヨワ・ガリーナ(2014)『構造分解とコード化を利用した計量的析に基づく漢字学習の体系化と効率化』政策研究大学院大学 博士論文 https://grips.repo.nii.ac.jp/?action=repository_uri&item_id=586&file_id=25&file_no=5
ヴォロビヨワ・ガリーナ, ヴォロビヨフ・ヴィクトル(2015)「漢字の構造分析に関わる問題―漢字字体の構造分解とコード化に基づく計量的分析」『国立国語研究所論集』(9)215–236. http://doi.org/10.15084/00000469
Halpern, Jack(1990)New Japanese-English Character Dictionary. Kenkyusha.
*1 今回の内容は、早川他(2019、2021) をもとにしています。詳細はそちらをご参照ください。
*2 第2回「日本語学習の障壁としての漢字とその教育」をご参照ください。
*3 漢和辞典に掲載されている部首も、「木(木偏)」や「亻(人偏)」のような形態が単純なものだけでなく、「風(かぜ)」や「飛(とぶ)」のような形態が複雑なものもあります。あとで示すように、私たちの行った字形分解では、一部の部首を構成要素として利用しています。
*4 分解の規則の詳細は早川他(2019)をご参照ください。
*5 教育漢字は2020年に改訂され1,026字になりましたが、今回紹介する試みは改訂以前に行ったもので、改訂前の教育漢字1,006字を用いました。
*6 教育漢字1,006字における延べの部品数は3,677個でした。
-
- 2021年07月20日 『あたらしい漢字指導のカタチ―外国にルーツを持つ児童生徒が学ぶために 3. 第二言語としての日本語の漢字教育見直しの視点 早川杏子(一橋大学)』
-
1.はじめに
第2回では、日本語という言語それ自体が、言語類型論(typology)の観点からみてもごく典型的なSOV言語であり、動詞の活用等も規則に一貫性があることから、習得が難しい言語とは言えないものの、漢字がそのボトルネックとなっている可能性を指摘し、外国にルーツを持つ児童生徒のための「漢字シラバス」の改変が課題であることを述べました。今回は、表記としての漢字を理論的に捉えた場合に、どのような観点から「漢字シラバス」を作成し、漢字指導を転換していくべきであるのかを考えます。
2.漢字の記憶―理論的説明
現在、常用漢字は2,136字で、小学校で修めるべきとされている漢字(以下、教育漢字)は1,026字です。一方、アルファベットの文字数は26、アラビア文字は28です。一つ一つ造形が異なる文字を1,000近く身に付ける必要があるということが、漢字を母語の表記として用いない(非漢字圏)学習者にとっていかに大変なことか、単純に他言語の文字数を比較しただけでもわかります。しかし、日本人母語話者にとって、漢字が日本語の表記方法の一つであることは自明のことであり、自分たちが子どもの頃から非常に長い時間をかけて学校で漢字の知識を身に付けてきた、という事実が意識化されることはあまりありません。
2.1 漢字は「語」である
漢字は、その呼び方から「字」であることに注意が向けられがちですが、漢字は字であると同時に「語」でもあります。表記体系(writing system)上の分類からすると、アルファベットのような文字は「表音文字(phonogram)」といい、漢字は「表語文字(ideograph)」にあたります。表音文字は、一つ一つの文字そのものは、意味を持ちません。語に当てられている一つ一つの書記素(grapheme)*1が結びついて初めて、意味を持ちます。一方で、漢字は一つ一つの文字が概念(concept)を持ち、意味を成します。また同時に音の情報も持っています。この形音義の3つの情報を備えたものが「語」です。
言語を心理学的に扱う分野では、語は心の中で書字(orthography;文字)・音韻(phonology;読み)・意味(meaning;語義)という3つの表象(representation)*2 から成る語彙表象(=語の記憶)として表されており、私たちの心の中にはこうした語の情報が寄り集まった辞書のようなもの(心内辞書、メンタルレキシコンとも言います)があると仮定して、語の情報がどのように処理されるのかを明らかにしようとしています。心理実験や臨床事例などから、書字・音韻・意味の3つの記憶が互いにネットワークを形成し、語の認識や発話を支えていると考えられています(例えば、Coltheart et al, 2001; Seidenberg & McClelland, 1989)。(図1を参照。クリックで拡大)
2.2 記憶の観点からみた書き取り練習
話を戻して、漢字が「語」であるということを、語彙表象という点から考えてみましょう。漢字が語であるならば、漢字一つ一つに、書字・音韻・意味の3つの表象がそれぞれ備わっているということになります。筆者にも経験がありますが、日本の小・中学校では、漢字指導の方法として繰り返し書くという指導がよく行われるのではないでしょうか。しかし、この繰り返し書くという行動は、書字表象の形成(漢字の字形の記憶)には役立つかもしれませんが、その漢字の音韻表象・意味表象(漢字の読み方と意味の記憶)の形成にはあまり効果が望めないと思われます*3。また、記憶の研究からは、意味を伴わない記憶は消えやすいということがわかっています(Craik & Lockhart, 1972)。つまり、文字の形をなぞるだけでは、いくら書いても忘れてしまうのです。読み方や意味の知識を伴わず、ただひたすら繰り返し書き取りだけを行う練習には、記憶の観点からみれば、あまり効果が期待できないと言えるかもしれません。
3.外国につながる子どもたちに対する漢字教育
小学校や中学校には、文部科学省が定めた学習内容、進度に沿って進める「学習指導要領」があります。漢字の学習範囲についても、「常用漢字表」に基づき文部省が作成した「音訓の小・中・高等学校段階別割り振り表*4」にしたがって、各学年で学習する漢字の字数、読み方などが指導されます。こうした学習計画のもとに、日本の子どもたちはいわば積み上げ式に漢字を学んでいくわけです。
このようなしっかりとした学習計画が既にあるならば、外国につながる児童生徒たちもそれにしたがって漢字を学んでいけば問題ないのではないか、と思われがちです。しかし、そこにも外国にルーツを持つ子どもたちならではの事情があります。子どもたちは親に帯同する形で日本にやってきますが、その子がちょうど日本の小学校や中学校入学の学齢期であるとは限りませんし、来日のタイミングによっては新学期開始ではなく学期途中での編入にならざるを得ない場合もあります。
漢字を教えずに、かなや母語で教科内容を教えればいいのではないか、という考えもあると思いますが、もしその外国にルーツを持つ子どもが日本に永住することになった場合、その子どもは最も学習が進む学齢期に漢字を習得する機会が得られないまま成人となってしまうことも考えられます。漢字かな交じり文が日本語の表記法である以上、漢字の読み書きが困難であるということが、その後の人生に与える影響がいかに大きなものとなるかは想像に難くありません。
4.外国にルーツを持つ児童生徒のための漢字シラバスの視点
以上のように、日本語を母語とする児童生徒と同様に学習指導要領通りに進めることには無理があります。しかし、中国語を除く他の言語と比べても、漢字はその文字数が圧倒的に多いと言わざるを得ません。その圧倒的な漢字数に対して、時間がない外国にルーツを持つ児童生徒たちに、どのように漢字を指導すればいいのでしょうか。
4.1 文章に対する漢字のカバー率
第二言語の語彙教育研究では、読み手がどれだけ文章内の語を知っているかが、内容の理解に大きな影響を及ぼすことが知られています(Nation, 2006; 小森・三國・近藤, 2004)。文章内の全語彙に対する読み手の既知語数を割ったものを既知語率と言いますが、既知語率が上がれば、内容理解が促進されやすくなります。ここで重要なのが、文章に対するカバー率(text coverage)という考え方です。どのような教科の文章にも高頻度で出てくる語を優先的に学んでいけば、文章中に既知語が含まれる確率が高くなり、理解できる文が増えたり内容の推測がしやすくなったりします。教科の文章内容を早く理解できるようになるためには、特定の教科、学年に限ることなく、教科横断的に頻繁に出てくる(カバー率が高い)語をまず先に覚え、既知語率を上げることが、外国にルーツを持つ児童生徒にとって有用なアプローチであると考えます。
ただ、複雑なことに、日本語の漢字の場合、単純に書字によるカバー率をみただけでは、その漢字の実際の使われ方を正確に捉えることができない可能性が出てきます。それは、中国語の漢字が一字に対して、読みはほぼ一つなのに対し、日本語の漢字は「解決」に対する「解く」のように複数の読みが当てられているということがあります。この読み方が一意的ではない(庵・早川2017)ということが、日本語において漢字の習得を困難にしている原因の一つだと言えるでしょう。
4.2 「読み」を絞る
ただこれも、日本語母語話者に意識化されることはあまりありません。というのも、自分たちが経験してきたのは、1字の漢字に付帯する読み方を一度に覚えるという方法だったからではないでしょうか。しかし日本語母語話者と第二言語学習者が決定的に違うのは、母語話者の場合、すでに獲得された母語の土台の上に漢字の字形を学ぶという点です。すでにメンタルレキシコン内にある語の読みに文字(漢字の字形)を後から当てるという母語話者の認知作業に比べると、第二言語学習者の場合、漢字の学習は、読み(音韻表象)・字形(書字表象)・意味(意味表象)という新たな語彙表象を形成する、相対的に負荷の高い認知作業になります。よく使う読みとあまり使わない読みを一度にすべて覚えようとするのは、情報量が増えてしまうので、第二言語の学習効率からするとむしろ非効率的です。
漢字が語であることを思えば、漢語の「自由」、和語の「自ずと」のように、当然ながらよく使われる読み方とそうでないものが存在します。時間のない外国にルーツを持つ児童生徒の事情を考えれば、必要もしくは重要なものを選定して、どの読みをどの順序で教えるかという視点が重要です。
5.中学校教科書コーパス研究の事例 [理科・英語]
5.1 漢字シラバス策定のための基礎研究
そこで私たちの研究では、中学校教科書の中に出現した漢字の読みの出現頻度を調べ、教科横断的に教科書によく出てくる(教科書の文章に対するカバー率が高い)漢字の読みを抽出することによって、優先的に学ぶべき漢字とその読みの選定を行っています。こうした計量的データに基づき、最終的には読み、字形、意味が考慮された漢字シラバスを作成する計画です。ここでは、中学校の理科・英語の教科書において出現した漢字の読み頻度の調査事例(庵・早川2017;早川・庵2020)を簡単にご報告します。
5.2 中学校教科書における漢字の読み頻度調査
庵・早川(2017)、早川・庵(2020)では、中学校教科書をコーパス化し、3学年分の理科教科書ならびに英語教科書*5に出現した全漢字を抽出し、各漢字の音読み・訓読み・その他の読み(常用漢字付表など)の出現回数(異なり漢字)と、その漢字の音読み/訓読みが占める比率を調べました。比率を調べたのは、音読み・訓読みのどちらを優先して学ぶとよいのかをみるための指標とするためです。読み方のパターンとしては、理科・英語教科書ともに、音読みのみ1種類の漢字が最も多く(理科370字(47.6%)、英語611字(48.7%))、次に音訓読みが1種類ずつのものが多くなっていました(理科257字(33.0%)、英語259字(20.6%))。読み方(音読みと訓読みを合わせたもの)のバリエーションは最も多いもので10通りのものがありました*6が、読み方の平均は理科が1.52通り、英語が1.51通りで、読み方が2個までのものがおよそ9割を占めていました。読み方が5~10個と非常に多い漢字は、理科では5字、英語では9字と数の上ではわずかでした。これらは同一の漢字ですが、読みにバリエーションがあるということは、その分異なる意味の語を持つということです。したがって、こうした漢字については、必要度や、日本語レベルに合わせて順次提示していくほうが学習負担が低いといえます。
理数系教科の一つである理科教科書の総出現頻度(音読み・訓読みを問わず総合的に多く出現した回数)の上位10位は、「物、水、気、電、体、化、質、動、液、大」と、専門内容に関する漢字が上位を占め、英語教科書では、「話、言、聞、書、語」など、言語コミュニケーションに関する漢字が上位を占めていました。つまり、教科によって出現する漢字・語の使用傾向も大きく異なることがわかりました。一方で、英語と理科の双方で頻度の高い上位50位に入っている漢字は「表、動、分、合、生、何、発、見、中」の9字で、これらは人文系、理数系の教科横断的に、優先的に学習すべき漢字であることがわかりました。音読み・訓読み別にみると、理科・英語教科書における音読頻度上位50位以内の重なりは「動、分、表、生、発、部」の6字のみで、訓読頻度上位50位以内の重なりは、「使、次、合、何、前、場、表、行、見、下、考、後、出、中、入、伝、形、音、同、上」の20字でした。このことから、音読頻度に比べると訓読頻度の高いもののほうが、理科と英語教科書では重なりが多いことがわかります。以上から、音読頻度の高い6字は優先的に音読みを、訓読頻度が高い20字は訓読みを学習していくという順序付けが可能となり*7、これを漢字シラバスに反映させていくことができるでしょう。
5.3 学年配当順に漢字を学習することの合理性
さらに、音読み、訓読みの頻度順位と漢字が配当されている学年との間に相関関係があるかどうかも調べてみました。学年配当の漢字は時系列的に学ぶという前提があるので、学年配当をコード化して(小学1~6年はそれぞれ1~6の値、中学1年=7、高校1年=10)、比較できるようにしました。理科・英語教科書に出てきた漢字の頻度順位が学年配当順と同じように並んでいるのであれば、この2つの間の相関の値が高くなります。しかし、もしそれぞれの並びの異なりが大きければ、相関が低い、もしくは無いということになります。どういうことかというと、学年配当順にしたがって学んでいったとしても、実際によく教科書に出てくる漢字とその読み(必要性が高いもの)が読めない、ということが頻繁に起こる可能性があるということです。こうして両変数の相関をみたところ、理科教科書には弱い相関がみられたものの、英語教科書においては、統計上相関がありませんでした。あくまで英語の教科書のことになりますが、中学校教科書コーパスの計量的な調査からも、学年配当順に漢字を学習することの合理性は見出しにくいことがデータ上からも示唆される結果となりました。
6.今回のまとめと次回の予告
今回では、はじめに漢字を理論的に捉えると書字・音韻・意味の3つの情報を考慮して指導する必要があることを述べ、外国にルーツを持つ児童生徒たちが置かれる状況から、彼/彼女らの漢字習得には、教科内容の理解に関わる優先度を決め、漢字シラバスを作成していく必要性を指摘しました。その方法の一つとして、カバー率という観点から行った中学校教科書の漢字の読み頻度調査の結果をご報告しました。しかし、多くの児童生徒や教員、支援者を悩ませる字形(書字)の指導をどうすべきかという課題が残っています。私たちの研究グループでは、字形についても取り組んでいます。新規に覚える30の部品と児童生徒たちが本来持つ基本的な認知能力で容易に覚えることのできる部品の組み合わせによって漢字の視認性(字形を視覚的に同定できること)を高めることで、教育漢字の半数近くが認識可能になるのではないかと推定しています。次回は、その字形についての研究について、詳しくご紹介します。
引用文献
庵功雄・早川杏子(2017)「JSL生徒対象の漢字教育見直しに関する基礎的研究―理科教科書の音訓率を中心に―」『人文・自然研究』11, 4-19, 一橋大学.
小森和子 ・三國純子・近藤安月子(2004)「文章理解を促進する語彙知識の量的側面―既知語率の閾値探索の試み―」『日本語教育』120, 83-92.
早川杏子・庵功雄 (2020)「中学校教科書コーパスを用いた漢字音訓率の算定―英語教科書を中心に―」『人文・自然研究』14, 108-122, 一橋大学.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., Ziegler, J. (2001) DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204-256.
Craik, F. I. M., & Lockhart, R.(1972) Levels of processing: A framework for memory research. Journal of Verbal Learning and Verbal Behavior, 11(6), 671-684.
Nation, I.S.P (2006) How large a vocabulary is needed for reading and listening? The Canadian Modern Language Review, 63(1), 59-82.
Seidenberg, M. S., & McClelland, J. L. (1989) A distributed, developmental model of word recognition and naming. Psychological Review, 96(4), 523-568.
*1 子音や母音など、意味を区別する音声言語の最小単位である音素(phoneme)に対する文字(列)を書記素(grapheme)と言います。英語の単語 [kɪd](子ども)に対する書記素は/k//i//d/で、[kʌt](切る)の書記素は/c//u//t/です。音声言語では同じ[k]の発音でも、単語として表わされる場合に/k//u//t/と書くことはできません。また、[noʊ](知る)については発音されないkを付けて/k//n//o//w/と書かなければいけません。このように、言語によっては語の実際の読み(音)とつづり(文字)が規則的でないものがあります。日本語では、仮名は1文字(1つの書記素)が1音(1つの音素)を表し、書記素と音素は規則的ですが、漢字はそうではありません。
*2 記憶された外界の情報が心の中で表現されたものを表象(representation)といいます。
*3 読み方を口頭もしくは頭の中でつぶやきながら書いたり、文脈の中に当てはめて書いたりする場合は、音韻や意味を伴いますので、単純にただ字形の反復練習をするのとは効果が異なると考えられます。
*4 2017(平成29)年3月に改定された音訓の取り扱いは、小学校においては2020(令和2)年度、中学校においては2021(令和3)年度から実施することとされています。https://www.mext.go.jp/a_menu/shotou/new-cs/1385768.htm
*5 理科教科書は1種、英語教科書は3種であったため、母数は異なります。
*6 読み方をカウントする際、基本の読みに加え、音便化(手書き:テガキ、出発:シュッパツ、小雨:コサメ)・促音化(一本:イッポン)した読みも1とカウントしているため、「常用漢字表」や「音訓の小・中・高等学校段階別割り振り表」に掲載している音読み/訓読みの数よりも多いものがあります。なお、音便化・促音化した読みは元となる読みの音訓(「かき、はつ、あめ、いち」)に基づいています。
*7 「表」は音読み/訓読み両方に高頻度で出てくるので、どちらの読みも必要度が高いということがわかります。この場合は、どちらの読みも教えるのがよいだろうと思います。
-
- 2021年07月13日 『あたらしい漢字指導のカタチ―外国にルーツを持つ児童生徒が学ぶために 2. 日本語学習の障壁としての漢字とその教育 庵 功雄(一橋大学)』
-
1.はじめに
前回は、本連載の第1回として、私たちの研究グループが理想と考える30年後の日本像とその中での外国にルーツを持つ児童生徒(子ども)の存在の重要性、および、彼/彼女に対する日本語教育が「バイパスとしての「やさしい日本語」」としての特徴を持つことを述べました。「バイパスとしての「やさしい日本語」」を考える上で重要なものに、文法シラバスと漢字シラバスの改変がありますが、本連載ではこのうち「漢字シラバス」の改変に関する私たちの取り組みについて紹介していきます。
今回は、「漢字」が日本語習得における障壁になっている事実について考えていきます。
2.日本語は習得しにくい言語ではない
今回のテーマは「漢字」ですが、そもそも日本語は非母語話者にとって習得しにくい言語なのでしょうか。
この問いに対する答えは様々であり得ます。
2.1 日本語は習得しにくい言語か?
第一の答えは、そもそも「習得しやすい言語」と「習得しにくい言語」という区別が無意味だというものです。何語の母語話者が何語を習得する場合でも、習得しやすい部分もあれば、習得しにくい部分もあるのだから、そもそも上記のような問い自体がナンセンスだという考え方もあり得ます(これに加えて、何を基準に「習得」を判断するかという問題もあります)。
第二の答えは、日本語は習得しにくい言語だというものです。例えば、外交官などの専門職を養成する米国務省の機関である外務職員局(Foreign Service Institute: FSI)が英語母語話者が習得に要する期間に基づいて各言語の習得難易度をまとめたサイトによると、英語母語話者にとって「極めて習得しにくい言語(Languages which are exceptionally difficult for native English speakers)」は、アラビア語、中国語(北京語、広東語)、韓国語、日本語とされています*1。これらの言語の文字体系が英語などの表記に使われるローマンアルファベットと大きく異なっていることは偶然ではないと思います。
2.2 日本語は典型的なSOV言語
第三の答えは、日本語は(漢字を除けば)習得しにくい言語ではないというものです。このことを示す事例を2つ紹介します。
世界の言語をいろいろな特徴から分析する言語学の分野を類型論(typology)と言います。世界の言語を分類する上で最も有名なのは基本語順だと思います。例えば、英語や中国語はSVO(S=Subject、V=Verb、O=Object)言語で、日本語や韓国語はSOV言語です。
Vは文の主要部(head) なので、SVO言語の場合は他の構造においても主要部が前に来るのが普通です。例えば、英語の関係節(relative clause)の語順は、(1)のように、主要部である”the book”が前に来て、修飾部(modifier)*2である”(which) John wrote”が後に来ます。こうした言語を主要部前置型言語(Head-first language)と言います。
(1)the book (which) John wrote
主要部 修飾部
一方、日本語の連体(修飾)節(英語の関係節、同格節に相当*3)では、(2)のように、主要部である「本」が後に来て、修飾部である「ジョンが書いた」が前に来ます。こうした言語を主要部後置型言語(Head-last language)と言います。
(2)ジョンが書いた本
修飾部 主要部
ところで、英語では形容詞と名詞の語順は(普通)「形容詞+名詞(修飾部+主要部=SOV型的)」になります*4。一方、フランス語などのロマンス語ではこの語順は「名詞+形容詞(主要部+修飾部=SVO型的)」になるのが普通です*5。
(3)a difficult question(難しい問題:英語)
(4)une question difficile(難しい問題:フランス語)
こうした点で、英語は主要部前置型言語の典型とは言えません*6。
一方、日本語は書きことばにおける基本語順では一貫して「修飾部+主要部」の語順になります*7。この点で、日本語は典型的な主要部後置型言語です。これは、日本語が「普通の言語」であることを示していると考えられます(柴谷1981も参照)。
2.3 日本語には不規則動詞が(ほとんど)存在しない
日本語が習得しやすい言語であると考えられる根拠をもう1つ挙げます。
日本語の動詞にはいくつかの活用形があります*8。「書く」を使って例示すると、次のようになります(庵ほか2000参照)。
マス形(書きます)、辞書形(書く)、タ形(書いた)、テ形(書いて)、ナイ形(書かない)、バ形(書けば)、タラ形(書いたら)、中止形(書き)、可能形(書ける)、意向形(書こう)、命令形(書け)、受身形(書かれる)、使役形(書かせる)。
このように、多くの種類の活用形がありますが、各活用形の作り方は規則的であり、英語のような「不規則活用動詞」はほとんどありません*9。
3.日本語習得の障壁としての漢字
このように、日本語は習得しにくい言語ではないと言えそうです。しかし、上述のように、母語に漢字がない(非漢字圏)学習者からは、日本語は極めて習得しにくい言語と見られていますし、実際、非漢字圏で上級まで日本語学習を続ける人の割合は漢字圏の学習者に比べて極めて少ないのが現状です。そうした意味で、漢字が日本語習得の障壁になっているのは間違いない事実です。ここでは、このことについて考えてみます。
3.1 言語(記号)の恣意性と言語習得
近代言語学の祖とも言われるソシュール(Ferdinand de Saussure. 1857-1913)が指摘した言語の持つ重要な特徴の1つに「言語(記号)の恣意性」があります。これは狭義には、ものを指す音形(指すもの。signifiant。シニフィアン*10)とその指示対象(指されるものsignifié。シニフィエ*10)の間に何ら必然的な関係がないことを指します*11。(図1を参照。クリックで拡大)
このことから、一般に言語を習得するためには最低次の3つが必要であることがわかります(ここでは音声言語についてのみ考えます)。
(5)a. 音形(指すもの)
b. 指示対象(指されるもの)
c. 字形(文字表記)
書きことばを持つ言語では、(5a)(5b)に加えて、(5c)という文字表記を習得する必要がありますが、日本語の場合、ひらがなでなら、発音通りに書けばよいので、字形の習得は容易です(一方、英語では発音と綴りのズレが大きいので、「発音通りに書く」レベルでの字形の習得は日本語よりもかなり難しいと言えます)。
自分の母語(mother languageまたはmother tongue)以外の言語を習得しようとする場合、まず、(5a)と(5b)の関係を覚える必要があります。例えば、日本語で「犬」という動物を英語では”dog”と呼ぶといったことです。それに加えて、習得しようとする言語(目標言語target language)での字形(5c)も覚えなければなりません。
ここで、母語に漢字を持たない非漢字圏学習者が日本語を習得する場合を考えてみます。この場合でも、(5a)と(5b)の関係を覚えなければならない点は同じです。また、日本語の場合、上述のように、「ひらがなでなら」発音通りに書けばいいので、(5c)の習得もそれほど問題ではありません。日本語母語話者の子どもが英語の単語(の綴り)を覚えるのと、非漢字圏の子どもが日本語の単語のひらがな表記を覚えるのにはほとんど違いはないのではないかと思われます。
問題となるのは、日本語の場合、(5c)に当たるのが「ひらがな」(+「カタカナ」)だけではないということです。日本で職を得てタックスペイヤーとなるためには、2000字程度の漢字を読み書きできる必要があると言えます*12。小学校卒業レベルに限定したとしても約1000字です*13。ここで、1つの漢字に音読みと訓読みが1つずつあるとすると、単純に考えて、小学校卒業レベルでも、1000個の文字と2000通りの読み方を特定できなければならない計算になります。
大部分の日本語母語話者(大人も子どもも含めて)はアラビア文字を見たとき、全く区別がつかないように感じると思います。このように、自分の母語にない文字体系を見たときに区別がつかないように感じるのはごく自然なことですが、アラビア文字は28字しかありません。つまり、自分の母語に存在しない文字は28通りでも区別できないと感じるのです。そうだとすれば、小学校卒業レベルで1000字、大人なら2000字を区別できなければならないということがいかに困難(に感じられる)かということがおわかりいただけるでしょう。外国にルーツを持つ子どもと漢字の問題を考える場合、この点での共感を持てるかどうかが非常に重要だと私たちは考えています。
3.2 漢字学習におけるハンディキャップ
もう1点考えておく必要があるのは、外国にルーツを持つ子どもと日本語母語話者の子どもの条件の違いです。日本語母語話者の子どもは、小学校に入る前に既に多くの語について、(5a)の(5b)関係を知っていて、ひらがなでなら書けるという状態で小学校に入ってきます。この場合、漢字学習者は「ひらがなでなら書ける語を漢字で書く」ことだけで済みます。それでも、小学校での学習漢字は約1000字、つまり、覚えられるのはその程度だと考えられているわけです。
これに対し、外国にルーツを持つ子どもの場合は、まず(5a)と(5b)の対応関係を覚え、ひらがなでなら書けるようになって、さらにそれが漢字でどう表されるかを覚えなければなりません。しかも、第1回で見たように、時間は非常に限られているのです。
4.新しい漢字シラバスの必要性
本連載では、こうした現状認識のもと、外国にルーツを持つ子どもの日本語学習、特に、漢字学習の負担をどうすれば軽減できるかに関する私たちの取り組みを紹介していきますが、ここでは、漢字学習の負担軽減のために考えるべきことをいくつか挙げておきます。これらに関する私たちの具体的な取り組みについては、次回以降の連載で紹介します。
4.1 必要な漢字から導入する
第一に必要なのは、必要な漢字から導入するということです。
現在の小学校における漢字の導入順は、単純なもの、具体的なもの、部首になるものなどから始める形になっており、日本語教育における漢字の導入順も基本的にそれにならっています。こうした方式は小学校入学前に既に大量の日本語のインプットに接している日本語母語話者の子どもにとっては妥当なものと言えるかもしれません。
しかし、特に、小学校の途中から日本の学校生活に入り、(5)に挙げた対応関係を覚えつつ、日本語で教科学習を行わなければならない非漢字圏の子どもにとっては、教科書に(よく)出てくる漢字から学習しなければ、教科書を読めるようになるという目標は到底達成できません*14。つまり、「牛、馬」などは後回しにして、「光合成、割り算」などを先にする必要があるのです。
4.2 手書きは求めない
もう1つ重要なのは、漢字学習の評価対象としては手書きは不要だということです。私たちは、漢字を覚えるための手段として、手書きを行うことについては必ずしも反対するものではありません。しかし、テストなどの「評価」の対象として手書きを行うことには賛成できません。
非漢字圏の子どもにとって、未知の文字である漢字を手書きすることは「絵」を書くのと同様の作業である可能性があります。これは、私たち日本語母語話者がアラビア語やタイ語など未知の言語の文字を手書きし、それぞれを区別しろと言われたらどれだけ大変かを想像してみればおわかりいただけると思います。しかも、漢字の場合、小学校卒業レベルでも約1000字を区別しなければならないのです。
カイザー(2018)は、留学生教育において漢字の手書きをやめるべきであることを説得的に論じています。「留学生がハイテク立国というイメージの強い日本にやってきて、無意味な手書き作業をさせられる時代はもう終わってもいいのではないか」(カイザー2018: 75)という指摘に私たちも全面的に賛成です*15。
子どもの場合、文字認識の手段として漢字を手書きで覚えるというストラテジーをとることは(一定程度は)必要であるかもしれません(ただし、この点についても本来はその効果を見るための知覚実験などが必要だと思います)。しかし、それはあくまで「覚え方の1つの手段」としてであり、それを強制すべきではなく、ましてや、テストなどの評価の対象にすべきではないと考えます。
現在求められる漢字に関するリテラシー(識字能力)は、書物やコンピューターの画面上の漢字の読みと意味を正確に理解し、パソコンやタブレットなどで、その文脈にふさわしい漢字を正確に入力できることです。その目的を達成するためには、特に子どもの場合、「手書き」よりも「ゲーム」などの手段の方が有効である可能性が高いように思われます*16。
4.3 コーパス、漢字の分解、実験
以上見てきたように、「バイパスとしての「やさしい日本語」」において必要な漢字教育を考えるためには、これまでの方法の改新が必要であり、そのためには、客観的なデータに基づく議論が必要です。
私たちはこうした問題意識のもと、漢字教育の改新のための手段として、中学校の教科書をコーパス化したものの分析を行ったり、非漢字圏学習者にとっての漢字の認識のあり方を調べるために、漢字を分解したり、実験を行ったりしてきています。その詳細については、次回以降の連載で詳しく紹介します。
5.今回のまとめと次回の予告
今回は、日本は習得しにくい言語であるという通説に対し、言語学的観点からは日本語は「典型的なSOV言語」であり、漢字を除けば、決して習得しにくい言語ではないことを示しました。その上で、漢字が非漢字圏の学習者にとって、間違いなく日本語習得の障壁になっている事実を述べ、その改善のために考えるべき問題点について述べました。
次回は、これまでの議論を受け、新しい漢字シラバスを考える上で必要な情報処理的観点と計量的観点から、私たちの取り組みを紹介します。
引用文献
安東明珠花・岡典栄(2019)「ろう児と〈やさしい日本語〉」庵功雄・岩田一成・佐藤琢三・柳田直美編『〈やさしい日本語〉と多文化共生』pp.257-273、ココ出版
庵功雄(2012)『新しい日本語学入門(第2版)』スリーエーネットワーク
庵功雄(2016)『やさしい日本語―多文化共生社会へ』岩波新書
庵功雄・高梨信乃・中西久実子・山田敏弘(2000)『初級を教える人のための日本語文法ハンドブック』スリーエーネットワーク
岡典栄・赤堀仁美(2011)『文法が基礎からわかる 日本手話のしくみ』大修館書店
カイザー,シュテファン(2018)「漢字と日本語教育:非漢字系からの(非)観点」『ことばと文字』10、pp.68-75、日本語のローマ字社
柴谷方良(1981)「特集・対照言語学—日本語は特異な言語か?類型論から見た日本語」『月刊言語』10-12、大修館書店
志村ゆかり編(2019a)『中学生のにほんご 学校生活編』スリーエーネットワーク
志村ゆかり編(2019b)『中学生のにほんご 社会生活編』スリーエーネットワーク
角田太作(2009)『世界の言語と日本語(改訂版)』くろしお出版
寺村秀夫(1975-1978)「連体修飾のシンタクスと意味―その1~その4―」寺村秀夫(1992)『寺村秀夫論文集I』pp.157-260に再録、くろしお出版
寺村秀夫(1980)「名詞修飾部の比較」寺村秀夫(1993)『寺村秀夫論文集II』pp.139-184に再録、くろしお出版
*1 https://www.state.gov/foreign-language-training/
*2 「主要部」は省略すると文法的に成り立たない(非文法的ungrammaticalになる)もので、「修飾部」は省略しても文法的に成り立つ(文法的grammaticalな)ものです。例えば、「高い山」という「名詞句」では、(イ)のaとbの比較からわかるように、「山」が主要部、「高い」が修飾部です。この点について詳しくは庵(2012: §3)を参照してください。
(ア)高い山が見える。
(イ)a. ×高いが見える。(「山」を省略)
b. ○山が見える。 (「高い」を省略)
*3 日本語の連体修飾節については寺村(1975-1978)を、日英語の比較については寺村(1980)をそれぞれ参照してください。
*4 “mission impossible”のように「名詞+形容詞(主要部+修飾部)」の語順になるものもありますが、現代英語では例外的です。
*5 ただし、フランス語でも基本的な形容詞は前置されることが多いです(例:une grosse pierre。大きな石)。
*6 実は、(現代)英語は類型論的に見ると、かなり特殊な言語です。この点について詳しくは角田(2009)の第9章「日本語は特殊な言語ではない。しかし、英語は特殊だ」を参照してください。
*7 従属節(修飾部)と主節(主要部)の語順についても、(ウ)(エ)からわかるように、日本語では修飾部が主節の後に置かれる(主要部+修飾部の語順になる)と倒置と解釈されますが、英語ではどちらの語順でも倒置の解釈にはなりません。
(ウ)a. もし明日雨が降ったら、私は出かけないつもりだ。
b. 私は出かけないつもりだ、もし明日雨が降ったら。(倒置)
(エ)a. If it rains tomorrow, I won’t go out.
b. I won’t go out if it rains tomorrow.
*8 こうした活用形の捉え方は学校文法のものとは異なります。これについて詳しくは庵ほか(2000)、庵(2012)を参照してください。
*9 五段活用(グループI)動詞のテ形、タ形(タラ形)のもとになる音便形語幹(「書く」の場合の「書い」)は学習上の難関ですが、覚えるべきパターンは限られています。
*10 「シニフィアン」と「シニフィエ」をそれぞれ「能記」と「所記」と訳す場合もありますが、ここでは庵(2012)にしたがい、それぞれ「指すもの」「指されるもの」と呼びます。
*11 日本語などの音声言語の場合「語」は「音(音声)」で表されますが、日本手話などの手話言語では「語」は「手形」で表されます。日本手話について詳しくは岡・赤堀(2011)などを、ろう児に対する日本語教育と「やさしい日本語」の関係については、庵(2016)、安東・岡(2019)などを参照してください。
*12 2010年に改訂された常用漢字は2136字です。
*13 現在の学習指導要綱における小学校の学習漢字数は1026字です。
*14 私たちの研究グループでは、最初級から始めて最終的に中学校の教科書を読めるようになることを目指した総合日本語教科書(全3冊)を作成し、既にそのうちの2冊が刊行されています(志村編2019a, 2019b)。
*15 もちろん、書写的な観点から漢字を書くことを学ぶことは今後も必要ですが、そうした能力を求めるかどうかは日本語母語話者、非母語話者の違いによらず、本人の自主的な選択によるものであると考えれます。
*16 私たちの研究グループでは、子ども向けにWebアプリなどを使った自律学習支援教材の開発にも着手しています。
-
- 2021年07月06日 『あたらしい漢字指導のカタチ―外国にルーツを持つ児童生徒が学ぶために 1. 30年後の日本社会と外国にルーツを持つ子ども 庵 功雄(一橋大学)』
-
1.はじめに
これから6回にわたって、外国にルーツを持つ児童生徒の日本語習得とそれに関わる漢字の問題、さらに、日本語教育における漢字教育の刷新というテーマについて考えていきたいと思います。
はじめに、この連載で使う用語について簡単に述べておきます。
まず、連載のタイトルでも使っている「外国にルーツを持つ児童生徒」ですが、これは両親のいずれか一方が外国籍の児童生徒(以下では、「児童生徒」のことを「子ども」と言うことがあります)のことを指します。こうした子どもの中には、日本で生まれ育ち、母語も日本語だが、日本国籍ではないという人もいれば、小学校の途中から日本に来て、母語も日本語ではないが、国籍は日本という人もいます。
この場合、「国籍」を基準にすれば、前者は「外国人」、後者は「日本人」となりますが、日本語教育の必要性ということからすれば、前者は日本語が母語なので日本語教育は不要である一方、後者にはかなり手厚い日本語教育が必要です。
このように考えていくと、「外国にルーツを持つ児童生徒」ということばでも拾いきれない問題があることは明らかですが、今回の連載で扱う内容を過不足なくカバーする語はないため、今回は「外国にルーツを持つ児童生徒」を使います。また、上記の理由で、こうした子どもたちを指すのに「日本人」「外国人」という用語も不適切であるため、その代わりに、原則として、「日本語母語話者」「非日本語母語話者」という語を使います。なお、これらを単に「母語話者」「非母語話者」と言う場合もあります。
2.30年後の日本社会をどう考えるか
外国にルーツを持つ子どもの問題を考える上で重要なのは、外国人の受け入れのあり方です。出入国管理庁の発表によれば、2020年6月現在の日本国内の外国人(非日本国籍者)の人口は2,885,904人で、日本の人口の約2.3%となっており*1、その数は今後も増えていくものと思われます。
外国人の受け入れが不可避である最大の理由は、日本の人口減少です。国立社会保障・人口問題研究所の将来推計(2017年推定)によると、日本の人口は2020年から2050年の30年間で約2300万人減少するとされています(出生中位・死亡中位推計)*2。
このように、日本の人口減少を前に、その埋め合わせとして外国人を受け入れる必要があるという議論があります。しかし、そうした議論は、ともすれば、外国人を日本人の代わりに働く存在としてしか考えない見方につながりがちです。こうした外国人を人間として見ない受け入れの手法は50年以上前にヨーロッパで破綻しており、そのことを表した有名なことばに「我々は労働力を呼んだが、やってきたのは人間だった」(スイスの作家マックス・フリッシュ)というものがあります。
こうした形の外国人受け入れの問題点は人道的なものに留まりません*3。現在日本には国と地方公共団体を合わせて1000兆円以上の借金があります。今後、税金や社会保障費の主な負担者の生産年齢人口(15歳~64歳)の人口が減少して税収が減り、借金も減らなければ、国家予算に占める国債費(借金の利払いに相当)の割合が増え、後の世代が自由に使える予算がどんどん少なくなり、最終的には国家財政の破綻につながりかねません(地方レベルでは、税収の減少の結果、バス路線の廃止など生活水準の悪化が加速度的に進む危険があります*4)。そうした事態を避けるには、税収を増やす必要がありますが、そのための最も確実な方法は、納税者(タックス・ペイヤー)としての外国人を増やすことです。
このことから、30年後の社会として目指すべきは、国籍としての「日本人」と「外国人」の区別に関係なく、日本に税金を払う人々が共同で日本を支えていく社会であると考えられます。そのためには、外国人が日本人と同様の所得が得られる仕事に就けるようになることが必要です。私たちの研究プロジェクトは、こうした理念のもと、「やさしい日本語」という考え方にもとづいて、外国人が活躍できる社会を作るための課題の解決を「日本語」という視点から考えています。本連載でご紹介する内容もそうした取り組みの一環です。
3.外国にルーツを持つ子どもに対する日本語教育*5
本連載では外国にルーツを持つ子どもの日本語習得、中でもその中での漢字の問題について考えていきますが、ここでは、そもそもなぜ「子ども」なのかと、「子ども」をめぐる問題点について考えます。
3.1 なぜ「子ども(児童生徒)」なのか
上で見たような30年後の日本社会像を理想とする場合、日本社会にとってより重要な課題は、成人の外国人以上に外国にルーツを持つ子どもだと考えられます。なぜなら、大人は自らの意志で日本に来たのに対し、子どもは選択の余地なく日本で育ち、日本社会の中で生きて行かざるを得ない存在であるからです。
そうした彼/彼女らが日本語母語話者の子どもと対等に競争して日本社会の中で自己実現できるようになれば、日本社会の中にこれまでにない多様性(diversity)が形成され、日本と国外の国や地域との間にこれまでにない多様な関係が構築されることになると考えられます。これは特に、人口減少によって限界集落化しつつある多くの地方都市*6にとって、起死回生のチャンスとなり得ると思われます。逆に、彼/彼女らが努力しても報われず、低所得の階層として囲い込まれるようになれば、日本社会の潜在的不安定要素になりかねません。これは、欧米の移民問題においても広く観察される極めて重要な論点です。
3.2 子どもの日本語習得に関わる問題
このように子どもの問題が重要であるとしたとき、特に考えなければならない点を2点挙げたいと思います。
3.3 BICSとCALPの問題
第一の問題点は、言語能力のタイプに関わるものです。
ジム・カミンズ(Jim Cummins)という研究者は、言語能力をBICSとCALPという2つのタイプに分けて考えることを提案しています。
BICS(Basic Interpersonal Communication Skills.「日常言語」と訳されることがありますが、「基本的対人コミュニケーション能力」と訳した方が実態に即しています)とは、その場の状況などを利用してコミュニケーションを行うことができる能力で、友だち同士の会話など文脈を共有している場合に適しています。
CALP(Cognitive Academic Language Proficiency.「学習言語」)とは、学校などにおいて、言語を通して思考し、言語を使って学習を行うための能力で、特に、書物(活字)を通して知識を得ていくために不可欠な能力です。
この2つはともに必要ですが、抽象的な知識を得ていく上でCALPの習得は不可欠です。しかし、CALPの習得には時間がかかることが知られており、そのため、外国にルーツを持つ子どもによく見られる現象として、BICSはある程度身につき、友だちと日本語で話はできているのに、CALPの習得が遅れ、教室での授業内容の理解がなかなか進まないということがあります。
3.4 漢字の問題
外国にルーツを持つ子どもが日本語を身につけることは、上述のCALPの習得の難しさという点からも明らかですが、日本語の場合、そうした認知上の困難点に加えて習得の障壁になるものとして漢字の存在があります。
本連載の最大の眼目は、こうした漢字の障壁を少しでも減らすことにあります。その前提として、漢字がどのような意味で日本語習得の障壁になっているのかを明らかにする必要がありますが、これについては、次回詳しく取り上げます。
4.「やさしい日本語」について*7
本連載における私たちの取り組みは、「やさしい日本語」という考え方の一環として位置づけられます。ここでは「やさしい日本語」について、ごく簡単に紹介します。
4.1 「やさしい日本語」とは何か
私たちの研究グループの「やさしい日本語」に対する取り組みは、非日本語母語話者に対する情報提供のあり方の研究から始まりました。その後、非母語話者の成人を対象とする「居場所作りのための「やさしい日本語」」と、外国にルーツを持つ子どもやろう児を対象とする「バイパスとしての「やさしい日本語」」という2つを柱に研究を進めています。
こうした「マイノリティ(少数者)のための「やさしい日本語」」という取り組みの他に、専門家が非専門家に情報を提供する際の表現のあり方を研究したり、日本語母語話者が自身の日本語の表現力を高めるために「やさしい日本語」の考え方がどのように活かせるかを研究したりする「マジョリティ(多数派)にとっての「やさしい日本語」」という観点からも研究を進めています*8。
4.2 バイパスとしての「やさしい日本語」
以上見てきたように、今後の日本社会を考える際に外国にルーツを持つ子どもが活躍の場を見出せるか否かは極めて重要です。しかし、彼/彼女らは日本語母語話者の子どもに対して圧倒的に大きな日本語能力に関するハンディキャップを持っています。そのハンディをできる限り縮め、早ければ高校進学時、遅くとも高校卒業時には、外国にルーツを持つ子どもが「まっとうに努力すれば」、母語話者の子どもとほぼ対等に競争でき、日本で安定した職に就けるようにすることが日本語教育に課せられた大きな課題であると考えます。
そうした競争を可能にするためには、既存の日本語教育のあり方を内容面で大きく転換し、より早く一定レベルの日本語能力に到達できるような工夫をすることが必要です。こうした工夫を「バイパスとしての「やさしい日本語」」と呼んでいます。そうした工夫として、特に重要なものに、文法シラバスと漢字シラバスの改変があげられますが、本連載では、特に後者の漢字シラバスの作成に関わる取り組みを紹介していきます。
5.今回のまとめと次回の予告
今回は、連載の1回目として、私たちのプロジェクトが目指す近未来の日本社会像を紹介し、その実現にとって、外国にルーツを持つ子どもに対する日本語教育が極めて重要な意味を持っていることを指摘しました。さらに、本連載の取り組みが「やさしい日本語」という考え方の中の「バイパスとしての「やさしい日本語」」という考え方の一部をなすことを述べました。
次回は、漢字が外国にルーツを持つ子どもの多くにとって、日本語習得上の大きな障壁になっている理由を中心に述べていきたいと思います。
引用文献
庵功雄・イ・ヨンスク・森篤嗣編(2013)『「やさしい日本語」」は何を目指すか』ココ出版
庵功雄(2016)『やさしい日本語―多文化共生社会へ』岩波新書
庵功雄・岩田一成・佐藤琢三・柳田直美編(2019)『〈やさしい日本語〉と多文化共生』ココ出版
庵功雄編(2020)『「やさしい日本語」表現事典』丸善出版
*1 外国人の人口は「在留外国人統計2020年6月版」 https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00250012&tstat=000001018034&cycle=1&year=20200&month=12040606&tclass1=000001060399、日本人の人口は「人口推計2020年(令和2年)6月報」 http://www.stat.go.jp/data/jinsui/pdf/202006.pdf によります。
*2 http://www.ipss.go.jp/pp-zenkoku/j/zenkoku2017/pp29_Report3.pdf
*3 実は、こうした非人道的な受け入れ政策の最も深刻な問題点は、こうしたやり方を続けていくと、最後には誰も日本に働きに来なくなるということです。この点については、例えば次の記事を参照してください。「技能実習生、脱ニッポン SNSで拡散する「暴力動画」」(朝日新聞デジタル2020.9.25)https://digital.asahi.com/articles/ASN9J5WB2N9DUEHF007.html
*4 そうした現状を示す例として、「10万人減 活気消えゆく新潟県内 国勢調査速報 増える空き家にため息」(新潟日報電子版2021.6.26)を参照してください。
*5 外国にルーツを持つ子どもに対する日本語教育と「やさしい日本語」の関係については、以下のインタビュー記事も参照してください。「多文化共生社会に必要な学校教育における「やさしい日本語」〜一橋大学 庵教授インタビュー~」(ワールド・ファミリーサイエンス研究所2020.6.4, 6.8)https://bilingualscience.com/english/%e5%a4%9a%e6%96%87%e5%8c%96%e5%85%b1%e7%94%9f%e7%a4%be%e4%bc%9a%e3%81%ab%e5%bf%85%e8%a6%81%e3%81%aa%e5%ad%a6%e6%a0%a1%e6%95%99%e8%82%b2%e3%81%ab%e3%81%8a%e3%81%91%e3%82%8b%e3%80%8c%e3%82%84%e3%81%95/(前編)
https://bilingualscience.com/english/%e5%a4%9a%e6%96%87%e5%8c%96%e5%85%b1%e7%94%9f%e7%a4%be%e4%bc%9a%e3%81%ab%e5%bf%85%e8%a6%81%e3%81%aa%e5%ad%a6%e6%a0%a1%e6%95%99%e8%82%b2%e3%81%ab%e3%81%8a%e3%81%91%e3%82%8b%e3%80%8c%e3%82%84%e3%81%95-2/(後編)
*6 限界集落については、例えば以下の記事を参照してください。「4年間で164集落が消滅、人口減・高齢化で拍車」(日本経済新聞電子版2020.10.24)
*7 「やさしい日本語」に関する最新の考え方については、以下の記事も参照してください。「平仮名ばかりの「やさしい日本語」 外国人のためだけ?」(朝日新聞デジタル2021.6.16) https://digital.asahi.com/articles/ASP6H4JH7P6FUPQJ001.html?iref=pc_ss_date_article
*8 「やさしい日本語」研究の展開について詳しくは、庵・イ・森編(2013)、庵(2016)、庵・岩田・佐藤・柳田編(2019)、庵編(2020)などを参照してください。
-
- 2021年06月28日 『新連載のお知らせ』
-
4月から12回にわたり国語の文法について様々な問題提起をしてくださった山田敏弘先生、ありがとうございました。学び続ける姿勢に励まされた方もいらっしゃると思います。連載は『ここが変だよ! 国語の文法(仮題)』としてリベラルアーツコトバ双書で刊行されます。
7月からは短期集中の6回連載で、庵功雄先生(一橋大学)、早川杏子先生(一橋大学)、本多由美子先生(国立国語研究所)による新連載「あたらしい漢字指導のカタチ 外国にルーツを持つ児童生徒が学ぶために」が始まります。庵先生は、言語の障壁を取り除き、多文化共生社会を実現するため<やさしい日本語>を提案されています。(岩波新書『やさしい日本語』参照)本連載は、日本語学・日本語教育学を専門とする3人の先生方が外国にルーツを持つ子どもたちに対する漢字教育について論じていきます。(金城)
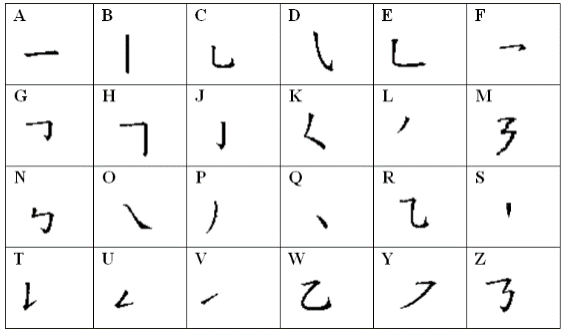 図1: 画のアルファベット・コード(ヴォロビヨワ2014)
図1: 画のアルファベット・コード(ヴォロビヨワ2014) 図2: 準部首(ヴォロビヨワ&ヴォロビヨフ2015)
図2: 準部首(ヴォロビヨワ&ヴォロビヨフ2015) 表1: 非漢字部品一覧(早川他2019)
表1: 非漢字部品一覧(早川他2019) 表2: 漢字部品一覧(早川他2019)
表2: 漢字部品一覧(早川他2019) 図1: 3つの表象
図1: 3つの表象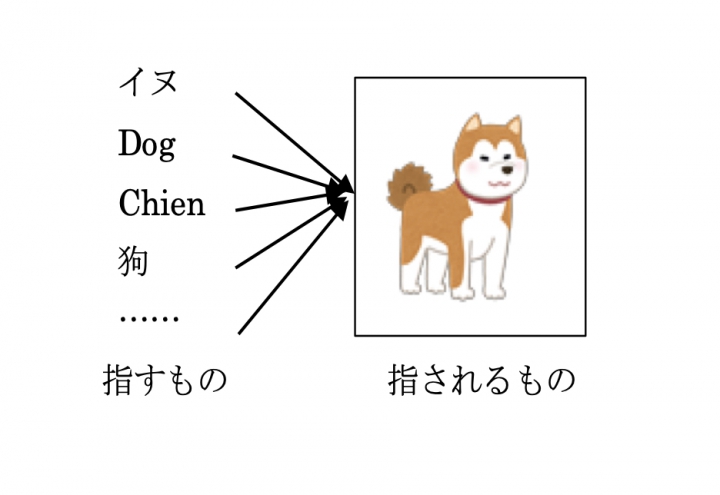 図1: 指すもの・指されるもの
図1: 指すもの・指されるもの